CTF Web信息搜集
前言
这段时间开始入门Web,主要是为了在线下赛不那么坐牢
Web的知识还是挺多的,所以需要成体系的学习
每学完一个方面我会写一篇总结性文章,将知识点与例题放在一起,方便后面查阅
如果之后学的更加深入或者遇到什么有代表性的题目,也会添加到文章中
信息收集
渗透的本质是信息收集,信息收集也叫做资产收集。
信息收集是渗透测试的前期主要工作,是非常重要的环节,收集足够多的信息才能方便接下来的测试,信息收集主要是收集网站的域名信息、子域名信息、目标网站信息、目标网站真实IP、敏感/目录文件、开放端口和中间件信息等等。通过各种渠道和手段尽可能收集到多的关于这个站点的信息,有助于我们更多的去找到渗透点,突破口。
常见信息
| 搜集方面 | 作用 |
|---|---|
| whois | 得到域名注册人的信息:邮箱、电话号码、姓名 |
| 子域名 | 可以扩大攻击范围,子域名一定是有关联的,很多时候基本上都同属一个公司 |
| 端口探测 | 危险端口可以直接爆破入侵,一个Ip可能搭建了多个网站,分布在不同的端口 |
| 目录扫描 | 目录扫描有的时候可以访问到压缩包源码、编辑器目录、废弃页面、其他站点 |
| 指纹识别 | 识别CMS,寻找通杀漏洞 |
| 旁站查询 | 旁站其实就是同IP站点,一定和目标站点在同一个内网或者是同一台服务器 |
| C段查询 | C段可能是同一个内网,同一个公司 |
| 内容敏感信息泄露 | 通过谷歌语法得到其他的东西 |
分类
域名信息
whois
概述
whois(读作“Who is”,非缩写)是用来查询域名的IP以及所有者等信息的传输协议。简单说,whois就是一个用来查询域名是否已经被注册,以及注册域名的详细信息的数据库(如域名所有人、域名注册商)
收集方法
备案
概述
网站备案也算是中国互联网的一大特色了
非经营性网站备案(Internet Content Provider Registration Record),简称ICP备案,指中华人民共和国境内信息服务互联网站所需进行的备案登记作业。
如果某网站申请了ICP备案,那么就能通过查询备案可以获取备案人的大量信息
收集方法
注意事项
一些个人网站底部贴的备案号很有可能是假的,或从其他站点复制过来的。所以查询备案信息时尽量通过域名来直接查询。
CDN
概述
內容分发网络(英语:Content Delivery Network或Content Distribution Network,缩写:CDN)是指一种透过互联网互相连接的电脑网络系统,利用最靠近每位用户的服务器,更快、更可靠地将音乐、图片、视频、应用程序及其他文件发送给用户,来提供高性能、可扩展性及低成本的网络内容传递给用户。
正好在我的博客R1ck’s Portal中,也使用到了这种内容分发网络服务,所以对它的作用的体会非常深刻。
在很大程度上,CDN能抵御像DDOS之类的攻击,同时还能让站点的真实IP “隐身”
但是这对于我们渗透测试时影响很大:无论我们对CDN的服务器有多大的控制权,也始终影响不到真实站点,也就是源站
此时需要我们绕过CDN,找到真正源站的IP
绕过方法
查询历史DNS记录
PHPinfo
如果目标网站存在phpinfo泄露等,可以在phpinfo中的SERVER_ADDR或_SERVER[“SERVER_ADDR”]找到真实ip
查询子域名
CDN的流量费还是不便宜的,所以很多站长可能只会对主站或者流量大的子站点做了 CDN,而很多小站子站点又跟主站在同一台服务器或者同一个C段内,此时就可以通过查询子域名对应的 IP 来辅助查找网站的真实IP。
具体查询子域名的方法会在接下来介绍
使用国外主机解析域名
国内很多 CDN 厂商因为各种原因只做了国内的线路,而没有针对国外的线路,此时我们使用国外的主机直接访问可能就能获取到真实IP。
网站邮件订阅查找
RSS邮件订阅,很多网站都自带 sendmail,会发邮件给我们,此时查看邮件源码里面就会包含服务器的真实 IP 了。
子域名
概述
收集子域名可以扩大测试范围,同一域名下的二级域名都属于目标范围。
收集方法
使用搜索引擎在线收集
FOFA搜索子域名
网络空间测绘,网络空间安全搜索引擎,网络空间搜索引擎,安全态势感知 - FOFA网络空间测绘系统
语法:domain=”主域名”
使用谷歌语法
Site:主域名
在线查询
使用工具爆破挖掘子域名
Layer
链接:https://pan.baidu.com/s/1QEYXjrGsARcXk6D-xLS64Q?pwd=1111
提取码:1111OneForAll
shmilylty/OneForAll: OneForAll是一款功能强大的子域收集工具 (github.com)
使用OneForAll时需要以管理员身份打开终端
使用高版本python运行时可能会出现报错
ImportError: cannot import name ‘sre_parse’ from ‘re’解决方法是找到python文件下的Lib\site-packages\exrex.py文件,对其代码进行更改:

使用证书反查
解析记录
概述
查询域名的NS记录、MX记录、TXT记录等很有可能指向的是真实ip或同C段服务器。
同时flag也有可能藏在这些解析记录中
常见解析类型
- A记录(Address Record):A记录将域名解析为IPv4地址。这是最常见的DNS记录类型,用于将主机名(例如:http://example.com)指向一个IPv4地址(例如:192.0.2.1)。
- AAAA记录(IPv6 Address Record):AAAA记录将域名解析为IPv6地址。与A记录类似,AAAA记录用于将主机名(例如:http://example.com)指向一个IPv6地址(例如:2001:0db8:85a3:0000:0000:8a2e:0370:7334)。
- CNAME记录(Canonical Name Record):CNAME记录用于将一个域名指向另一个域名。通常用于别名或子域名的情况,例如将http://www.example.com指向http://example.com。
- MX记录(Mail Exchange Record):MX记录用于指定处理域名电子邮件的邮件服务器。通常,MX记录会指向一个邮件服务器的域名,如:http://mail.example.com。
- NS记录(Name Server Record):NS记录指定了负责解析域名的DNS服务器。通常,在注册域名时,域名注册商会为您分配默认的NS记录。这些记录可以更改,以便将域名的解析委托给其他DNS服务器。
- TXT记录(Text Record):TXT记录用于存储与域名相关的任意文本信息。这些记录通常用于验证域名所有权(如Google网站验证)或实现电子邮件验证技术(如SPF,DKIM和DMARC)。
收集方法
使用本机的nslookup命令
nslookup -type=type domain [dns-server]其中type为解析类型,domain为域名,dns服务器为可选项
在线查询
旁站
概述
旁站指的是同一服务器上的其他网站,一般是同一ip
收集方法
在线查询
搜索引擎
fofa
语法:ip=”xxx.xxx.xxx.xxx”
C段
概述
对目标主机无计可施时,我们可以尝试一下从C段入手。C段入侵是拿下同一C段下的服务器,也就是说是D段1-255中的一台服务器,然后直接从被端掉的服务器出发进行其他测试
收集方法
在线查询
搜索引擎
fofa
语法:ip=”xxx.xxx.xxx.0/24”
服务器信息
端口
概述
当确定了目标大概的ip段后,可以先对ip的开放端口进行探测,一些特定服务可能开起在默认端口上,探测开放端口有利于快速收集目标资产,找到目标网站的其他功能站点。通过扫描服务器开放的端口以及从该端口判断服务器上存在的服务。
收集方法
在线端口检测
扫描工具
服务器类型
网站服务器有不同的操作系统:windows、Linux、mac os
windows对大小写不敏感,其他两个对大小写敏感
数据库类型
目前比较常用的数据库有:MySQL、SQL server、Oracle等。SQL server开放的默认端口:1433,MySQL开放的默认端口:3306、Oracle开放的默认端口:1521。
waf防火墙
收集方法
kali自带Wafw00f
语法:wafw00f xxx.com
网站信息
备份文件
除了F12查看源代码,有时网站的备份文件也会泄漏源代码
备份文件是常见的源码泄露的方式,实践中往往是开发者的疏忽而忘记删除备份文件,从而导致服务器中残留源码。我们可以通过访问这些备份文件来审计代码,一般情况下可以用后台扫描工具扫描。
备份文件常见的后缀名
备份文件基本上都是压缩包
.rar .zip .7z .tar .gz .bak
对于bak类的备份文件,可以直接输入文件名称+.bak访问例如:index.php.bak
.txt .old .temp _index.html .swp .sql .tgz
备份文件常见的文件名
web
website
backup
back
www
wwwroot
temp
db
data
code
test
admin
user
sql
gedit备份文件
在Linux下,用gedit编辑器保存后,当前目录下会生成一个后缀为~的文件,其文件内容就是刚编辑的内容。假设刚才保存的文件名为flag,则该文件名为flag~。
通过浏览器访问这个带有~的文件,便能得到源代码
vim备份文件
使用vim编辑器编写filename文件时,会有一个.filename.swp文件产生,它是隐藏文件。如果编写文件时正常退出,则该swp文件被删除,如果异常退出,该文件则会保存下来,该文件可以用来恢复异常退出时未能保存的文件,同时多次意外退出并不会覆盖旧的.swp文件,而是会生成一个新的,例如.swo文件。
针对swp备份文件,我们可以用vim -r命令恢复文件的内容
例如当前目录下假如存在.flag.swp文件,则恢复命令为vim -r flag
收集方法
手动组合文件名和后缀并尝试
使用后台扫描工具
使用BurpSuite
将访问目标站点的请求包转到Intruder模块
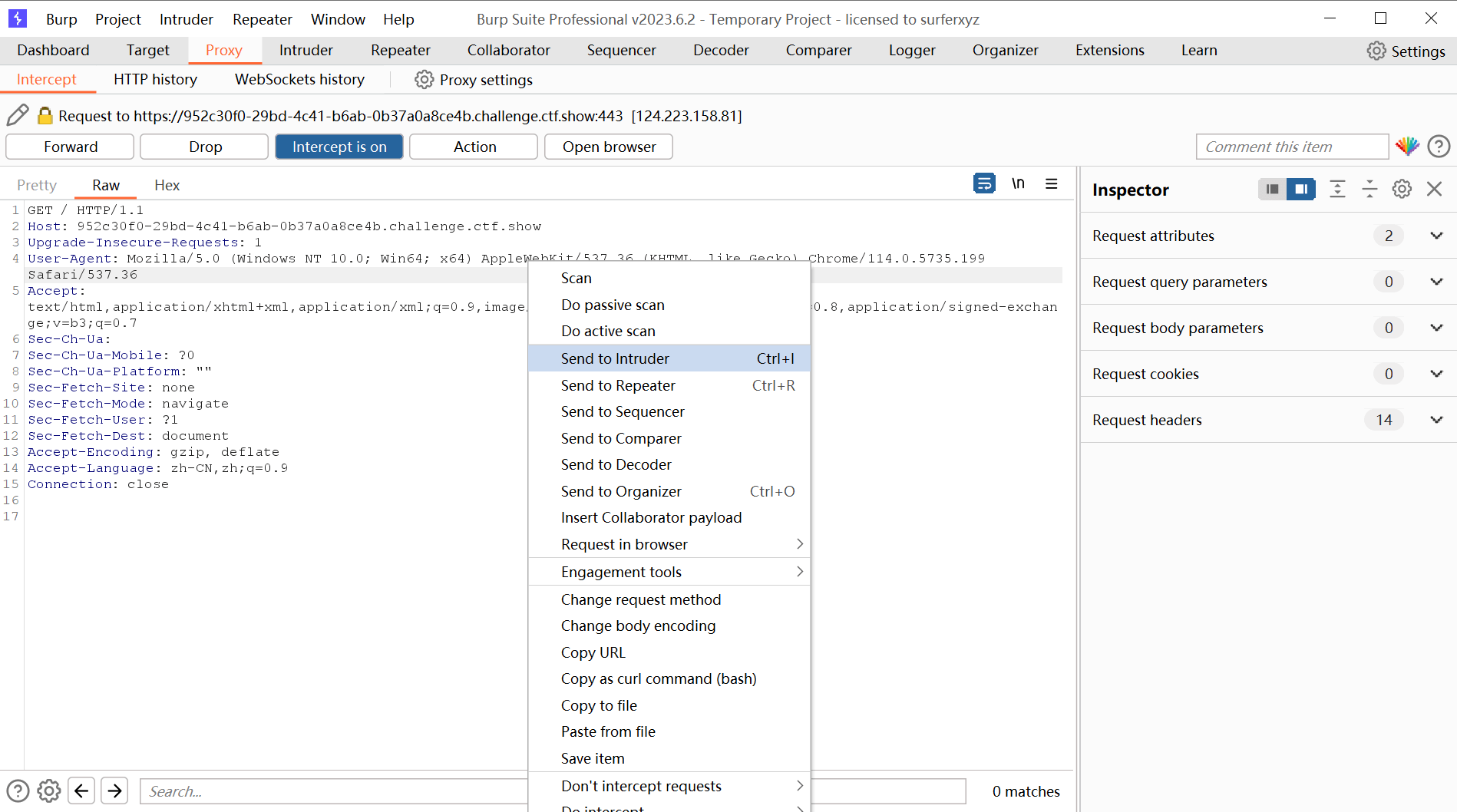
使用集束炸弹模式,并设置两个变量
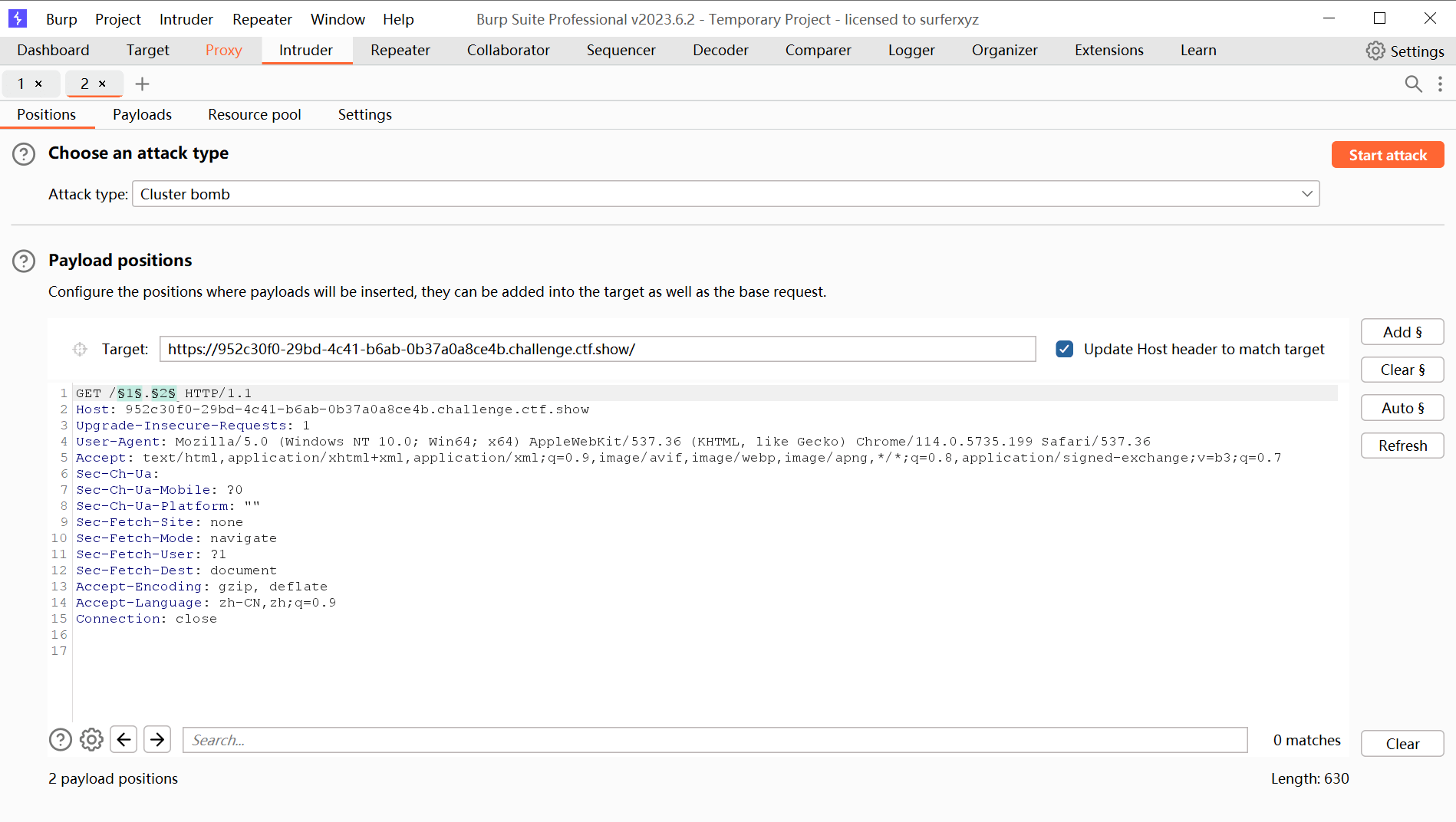
设置payload为测试用的文件名和后缀
使用自定义python脚本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16import requests
url1 = 'http://example.com' # url为被扫描地址,后不加‘/’
# 常见的网站源码备份文件名
list1 = ['web', 'website', 'backup', 'back', 'www', 'wwwroot', 'temp','data','db','code','admin','user','sql','index.php']
# 常见的网站源码备份文件后缀
list2 = ['tar', 'tar.gz', 'zip', 'rar', 'bak','old' ,'temp','_index.html','.swp','.sql','.tgz']
for i in list1:
for j in list2:
back = str(i) + '.' + str(j)
url = str(url1) + '/' + back
print(back + ' ', end='')
print(requests.get(url).status_code)
敏感目录
概述
通过扫描目录和文件,大致了解同站的的结构,获取突破点,比如后台,文件备份,上传点以及源码的目录
敏感文件常见的如.git文件泄露,.svn文件泄露,phpinfo泄露等
收集方法
后台扫描工具
御剑
链接: https://pan.baidu.com/s/1uvnBpzTvp7GLhIoivnIN0w?pwd=1111
提取码: 1111
御剑工具的字典非常重要,平时做题遇到没见过的的后台都可以加进去
dirsearch
这里安装dersearch后可能会出现扫描慢的情况(正常扫描速度应该在200/s左右)
解决方法参考这篇文章:dirsearch扫描速度慢的bug修复 | LiangMaxwell’s Blog
语法:
python dirsearch.py -u http://example.com:10800指定响应码可以加上
-i例如若要指定200和300-399之间的响应码,可以加上
-i 200,300-399递归目录扫描,可以加上
-r -R 层数
查看robots.txt和sitemap.xml等文件
搜索引擎在线收集
- 任意文件下载:
site:域名 filetype:zip|rar|zip|xml - 敏感信息(目录):
site:域名 index of、intitle:"Index of /admin" - 未授权访问:
inurl:php? intext:CHARACTER_SETS,COLLATIONS, ?intitle:phpmyadmin - 后台:
site:xxx.com inurl:login|admin|manage|member|admin_login|login_admin|system|login|user
- 任意文件下载:
CMS类型(指纹识别)
概述
收集好网站信息之后,应该对网站进行指纹识别,通过识别指纹,确定目标的cms及版本,方便制定下一步的测试计划
CMS是内容管理系统的缩写。它是一种软件工具,用于创建、编辑和发布内容。CMS系统可以帮助用户创建和管理他们的网站,帮助网站管理员管理构成现代网站的许多不同资源,内容类型和各种数据。CMS系统分为四种不同类型:企业内容管理系统(ECM / ECMS),Web内容管理系统,Web组内容管理系统和组件内容管理系统。CMS最擅长的就是建设网站,最流行的CMS有:Wordpress,Drupal,Joomla
收集工具
在线识别工具
kali自带的whatweb
语法:whatweb xxx.com
探针泄漏
概述
安装了LNMP后或者是配置了PHP环境后,我们一般习惯性地上传一个PHP探针来检测一下我们的PHP环境是否正确地配置,同时有时遇到一些特殊的程序需要相关的PHP组件支持,我们也可以上传一个PHP探针来检测一下我们的Web环境是否符合要求。
收集方法
尝试手动添加常见的探针文件
常见探针文件有:
phpinfo.php
tz.php
monitor.php
l.php
在后台扫描字典中添加常见探针文件
谷歌hacker
谷歌语法
site:
- 指定域名
filetype:
- 指定文件类型
inurl:
- 指定URL
link:
- 包含指定网页的链接的网页
intitle:
- 指定title
intext:
- 指定内容
详细教程
信息收集之Google Hacking的简单用法index of /admin谢公子的博客-CSDN博客
源码泄露
git 源码泄露
git是一个主流的分布式版本控制系统,开发人员在开发过程中经常会遗忘.git文件夹,导致攻击者可以通过.git文件夹中的信息获取开发人员提交过的所有源码,进而可能导致服务器被攻击而沦陷
常规git泄漏
利用.get文件恢复源码
使用工具GitHacker:WangYihang/GitHacker
语法:
githacker --url http://example.com/.git/ --output-folder G:\CTF\Web\工具\GitHacker\result或者使用工具dvcs-rippper
rip-git.pl -v -u http://www.example.com/.git/git回滚
git会记录每次提交(commit)的修改
git回滚可以让我们复原之前commit的版本
git log --stat可以查看每个commit修改了哪些文件git diff HEAD commit-id可以查看当前版本与指定commit之间的区别使用
git stash pop恢复文件使用命令
git reset HEAD^可以回到上一个版本git分支
git中常用的是master分支,但也可能存在其他的时间线分支
在恢复的源码文件夹中执行
git branch -v查看分支信息执行
git reflog查看checkout记录下载分支的head信息
再使用工具恢复
SVN 源码泄露
SVN是一个开放源代码的版本控制系统。在使用SVN管理本地代码过程中,会自动生成一个名为.svn的隐藏文件夹,其中包含重要的源代码信息。
主要利用.svn/entries及wc.db文件
可以使用工具dvcs-ripper
dvcs-ripper需要在linux系统使用
rip-svn.pl -v -u http://www.example.com/.svn/
hg源码泄漏
Mercurial 是一种轻量级分布式版本控制系统,使用 hg init的时候会生成.hg,其中包含代码和分支修改记录等信息。
可以使用工具dvcs-ripper
rip-hg.pl -v -u http://www.example.com/.hg/
CVS泄露
CVS是一个C/S系统,多个开发人员通过一个中心版本控制系统来记录文件版本,从而达到保证文件同步的目的。
针对 CVS/Root以及CVS/Entries目录,直接就可以看到泄露的信息。
利用工具dvcs-ripper
rip-cvs.pl -v -u http://www.example.com/CVS/
Bazaar/bzr泄露
bzr是个版本控制工具, 虽然不是很热门, 但它也是多平台支持, 并且有不错的图形界面。
使用工具dvcs-ripper
rip-bzr.pl -v -u http://www.example.com/.bzr/
DS_Store 文件泄露
.DS_Store是Mac下Finder用来保存如何展示 文件/文件夹 的数据文件,每个文件夹下对应一个。如果将.DS_Store上传部署到服务器,可能造成文件目录结构泄漏,特别是备份文件、源代码文件。
使用工具ds_store_exp
python ds_store_exp.py http://www.example.com/.DS_Store
http状态码
响应分为五类:信息响应(100–199),成功响应(200–299),重定向(300–399),客户端错误(400–499)和服务器错误 (500–599):
| 分类 | 分类描述 |
|---|---|
| 1** | 信息,服务器收到请求,需要请求者继续执行操作 |
| 2** | 成功,操作被成功接收并处理 |
| 3** | 重定向,需要进一步的操作以完成请求 |
| 4** | 客户端错误,请求包含语法错误或无法完成请求 |
| 5** | 服务器错误,服务器在处理请求的过程中发生了错误 |
HTTP状态码列表:
| 状态码 | 状态码英文名称 | 中文描述 |
|---|---|---|
| 100 | Continue | 继续。客户端应继续其请求 |
| 101 | Switching Protocols | 切换协议。服务器根据客户端的请求切换协议。只能切换到更高级的协议,例如,切换到HTTP的新版本协议 |
| 200 | OK | 请求成功。一般用于GET与POST请求 |
| 201 | Created | 已创建。成功请求并创建了新的资源。这通常是在 POST 请求,或是某些 PUT 请求之后返回的响应。 |
| 202 | Accepted | 已接受。已经接受请求,但未处理完成 |
| 203 | Non-Authoritative Information | 非授权信息。请求成功。但返回的meta信息不在原始的服务器,而是一个副本 |
| 204 | No Content | 无内容。服务器成功处理,但未返回内容。在未更新网页的情况下,可确保浏览器继续显示当前文档 |
| 205 | Reset Content | 重置内容。服务器处理成功,用户终端(例如:浏览器)应重置文档视图。可通过此返回码清除浏览器的表单域 |
| 206 | Partial Content | 部分内容。服务器成功处理了部分GET请求 |
| 300 | Multiple Choices | 多种选择。请求的资源可包括多个位置,相应可返回一个资源特征与地址的列表用于用户终端(例如:浏览器)选择 |
| 301 | Moved Permanently | 永久移动。请求的资源已被永久的移动到新URI,返回信息会包括新的URI,浏览器会自动定向到新URI。今后任何新的请求都应使用新的URI代替 |
| 302 | Found | 临时移动。与301类似。但资源只是临时被移动。客户端应继续使用原有URI |
| 303 | See Other | 查看其它地址。与301类似。使用GET和POST请求查看 |
| 304 | Not Modified | 未修改。所请求的资源未修改,服务器返回此状态码时,不会返回任何资源。客户端通常会缓存访问过的资源,通过提供一个头信息指出客户端希望只返回在指定日期之后修改的资源 |
| 305 | Use Proxy | 使用代理。所请求的资源必须通过代理访问 |
| 306 | Unused | 已经被废弃的HTTP状态码 |
| 307 | Temporary Redirect | 临时重定向。与302类似。使用GET请求重定向 |
| 400 | Bad Request | 客户端请求的语法错误,服务器无法理解 |
| 401 | Unauthorized | 请求要求用户的身份认证 |
| 402 | Payment Required | 保留,将来使用 |
| 403 | Forbidden | 服务器理解请求客户端的请求,但是拒绝执行此请求 |
| 404 | Not Found | 服务器无法根据客户端的请求找到资源(网页)。通过此代码,网站设计人员可设置”您所请求的资源无法找到”的个性页面 |
| 405 | Method Not Allowed | 客户端请求中的方法被禁止 |
| 406 | Not Acceptable | 服务器无法根据客户端请求的内容特性完成请求 |
| 407 | Proxy Authentication Required | 请求要求代理的身份认证,与401类似,但请求者应当使用代理进行授权 |
| 408 | Request Time-out | 服务器等待客户端发送的请求时间过长,超时 |
| 409 | Conflict | 服务器完成客户端的 PUT 请求时可能返回此代码,服务器处理请求时发生了冲突 |
| 410 | Gone | 客户端请求的资源已经不存在。410不同于404,如果资源以前有现在被永久删除了可使用410代码,网站设计人员可通过301代码指定资源的新位置 |
| 411 | Length Required | 服务器无法处理客户端发送的不带Content-Length的请求信息 |
| 412 | Precondition Failed | 客户端请求信息的先决条件错误 |
| 413 | Request Entity Too Large | 由于请求的实体过大,服务器无法处理,因此拒绝请求。为防止客户端的连续请求,服务器可能会关闭连接。如果只是服务器暂时无法处理,则会包含一个Retry-After的响应信息 |
| 414 | Request-URI Too Large | 请求的URI过长(URI通常为网址),服务器无法处理 |
| 415 | Unsupported Media Type | 服务器无法处理请求附带的媒体格式 |
| 416 | Requested range not satisfiable | 客户端请求的范围无效 |
| 417 | Expectation Failed | 服务器无法满足Expect的请求头信息 |
| 500 | Internal Server Error | 服务器内部错误,无法完成请求 |
| 501 | Not Implemented | 服务器不支持请求的功能,无法完成请求 |
| 502 | Bad Gateway | 作为网关或者代理工作的服务器尝试执行请求时,从远程服务器接收到了一个无效的响应 |
| 503 | Service Unavailable | 由于超载或系统维护,服务器暂时的无法处理客户端的请求。延时的长度可包含在服务器的Retry-After头信息中 |
| 504 | Gateway Time-out | 充当网关或代理的服务器,未及时从远端服务器获取请求 |
| 505 | HTTP Version not supported | 服务器不支持请求的HTTP协议的版本,无法完成处理 |
ctfshow web1-20
web1(注释)
按F12调出页面源码
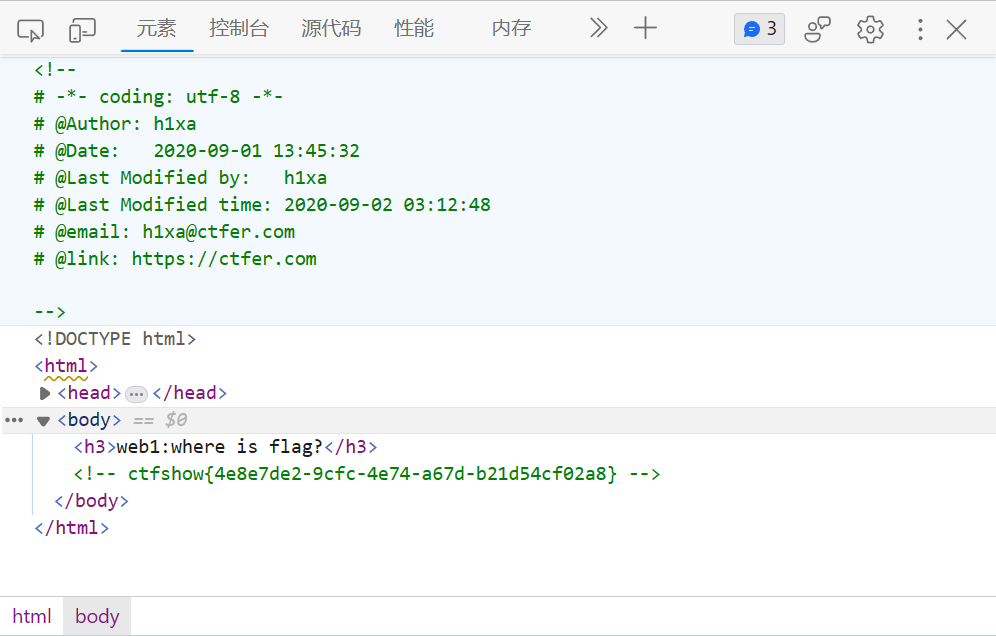
可以发现flag就放在html注释中
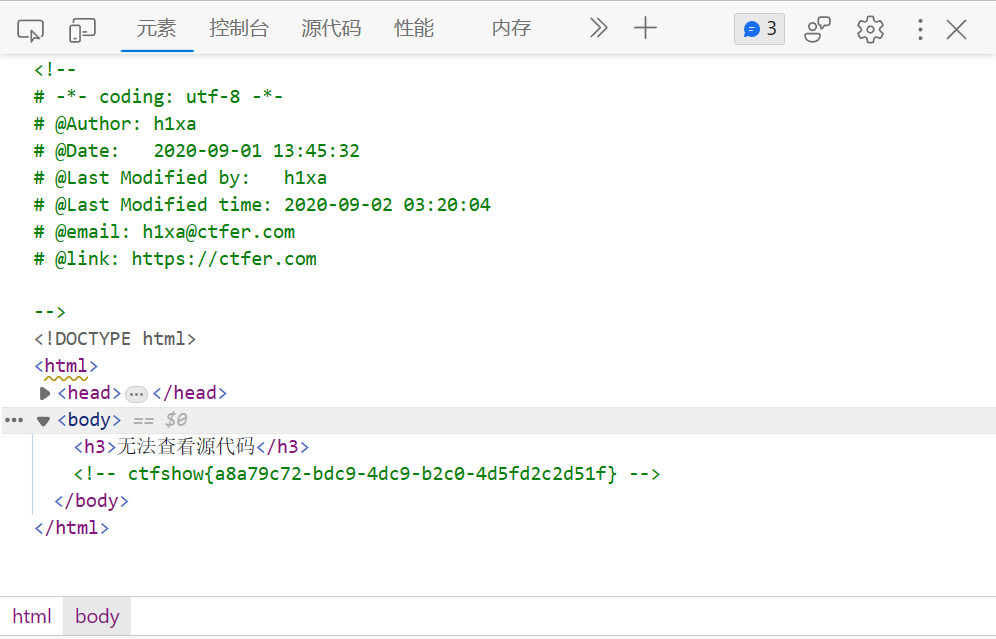
web2(JS禁用F12)
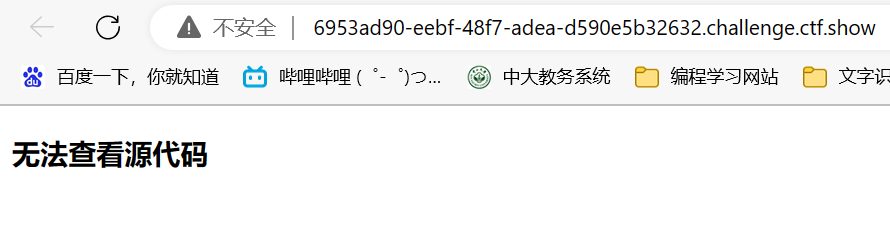
页面显示无法查看源代码,F12按键和右键均失效
考虑到可能是被js给禁用了
方法一:
此处我们在url前加上view-source:直接查看页面源码
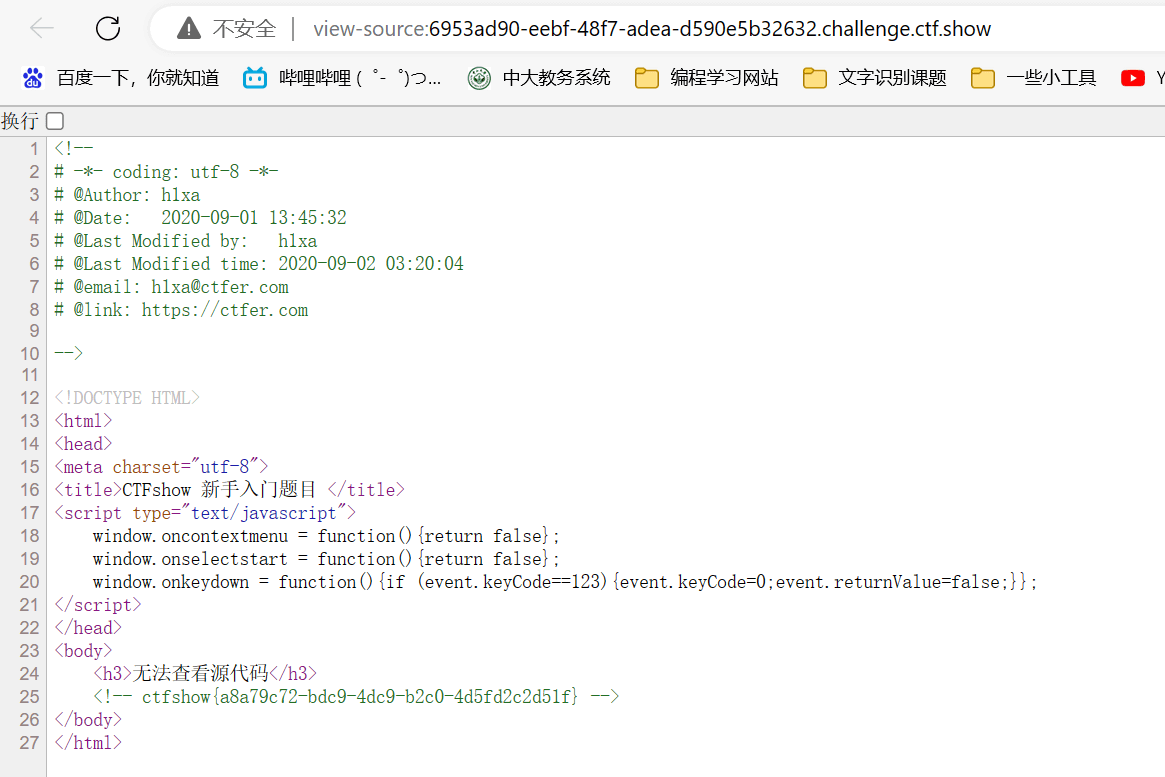
在源码中我们能看到js确实禁用了右键和f12等功能
flag仍然藏在注释中
方法二:
由于是JavaScript导致的禁用,那么我们可以直接在浏览器中关闭JavaScript的功能
以edge浏览器为例,在设置中搜索JavaScript,在阻止栏中添加我们想查看源码的站点url
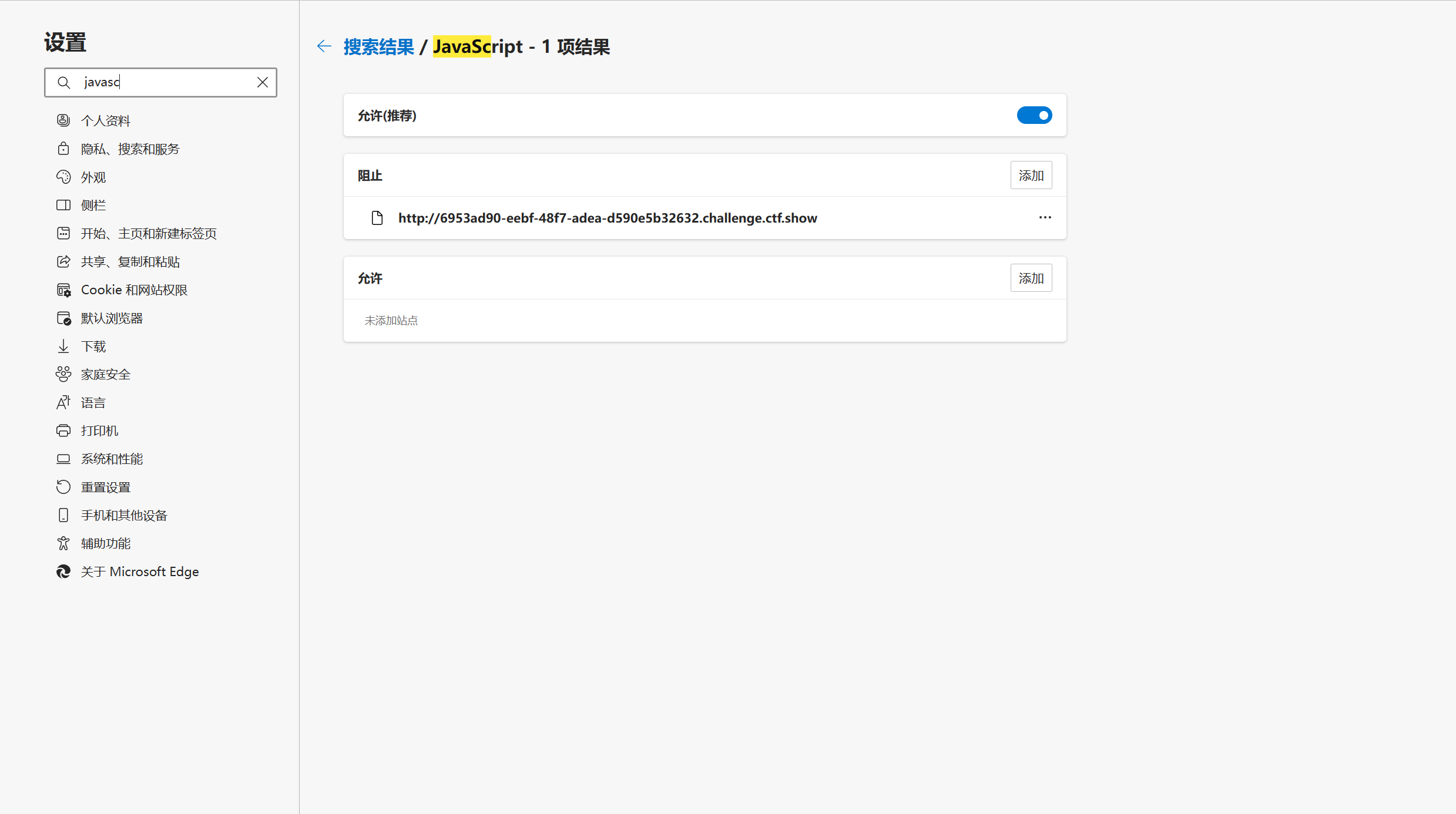
此时F12功能又恢复了
web3(响应体)
根据题目提示,使用burpsuite进行抓包
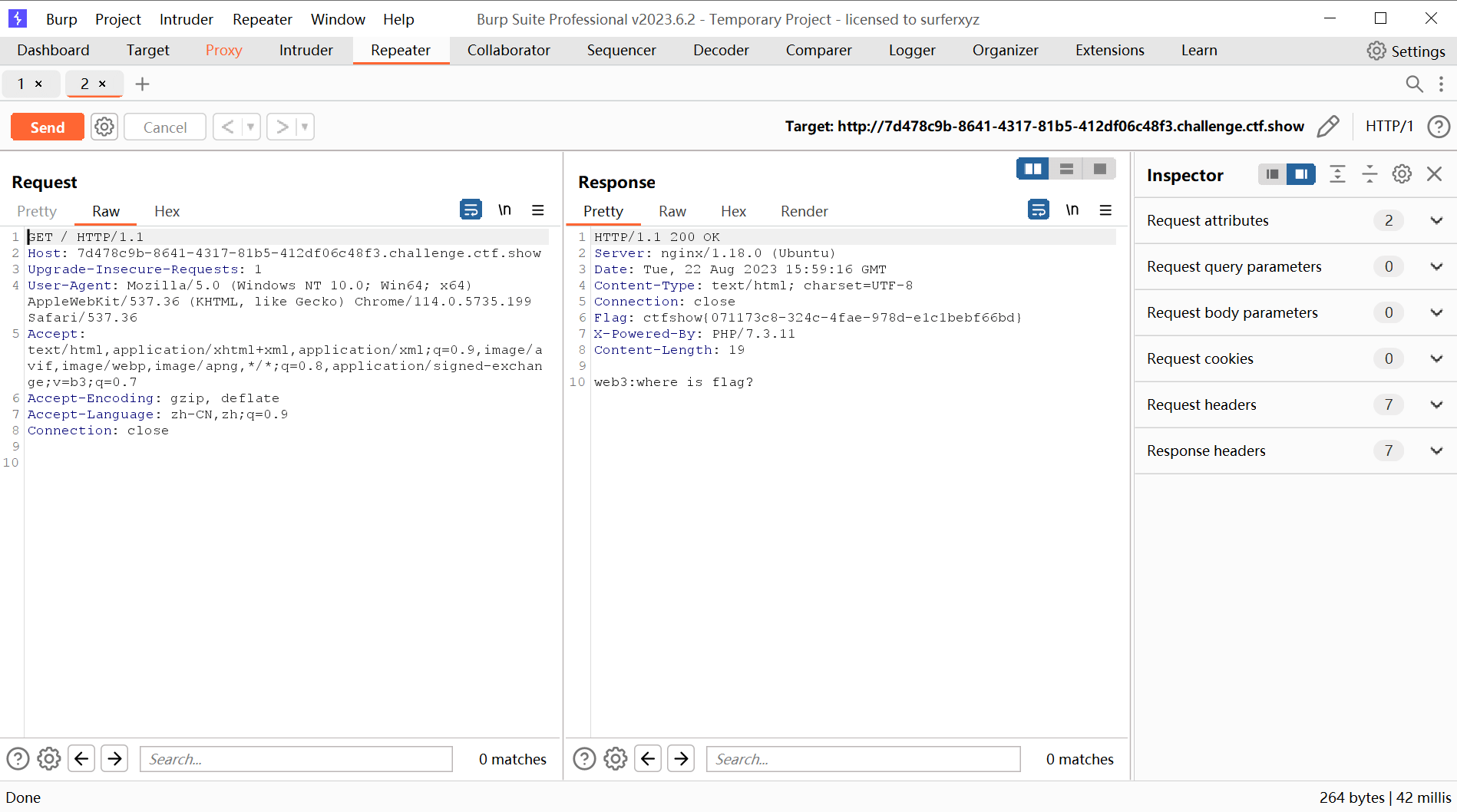
发现flag藏在响应体中
web4(robots.txt)
题目提示robot,我们直接在网站地址后加/robots.txt
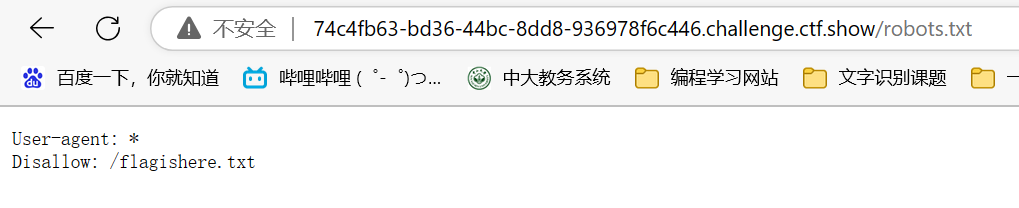
不让爬的文件中有一个flag命名的txt文件,flag应该就在其中

web5(phps源码)
题目提示phps源码
phps文件就是php的源代码文件,通常用于提供给用户(访问者)直接通过Web浏览器查看php代码的内容。
因为用户无法直接通过Web浏览器“看到”php文件的内容,所以需要用phps文件代替。
在题目未给出提示时,我们也可以通过扫描后台来发现遗留的phps文件
在url后加上/index.phps下载phps源码
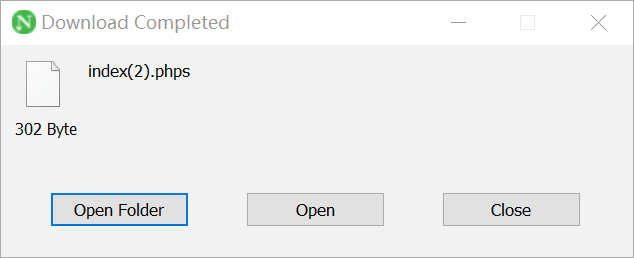
用vscode打开,flag就在phps源码中
web6(备份文件)
使用dirsearch扫描,发现有备份文件
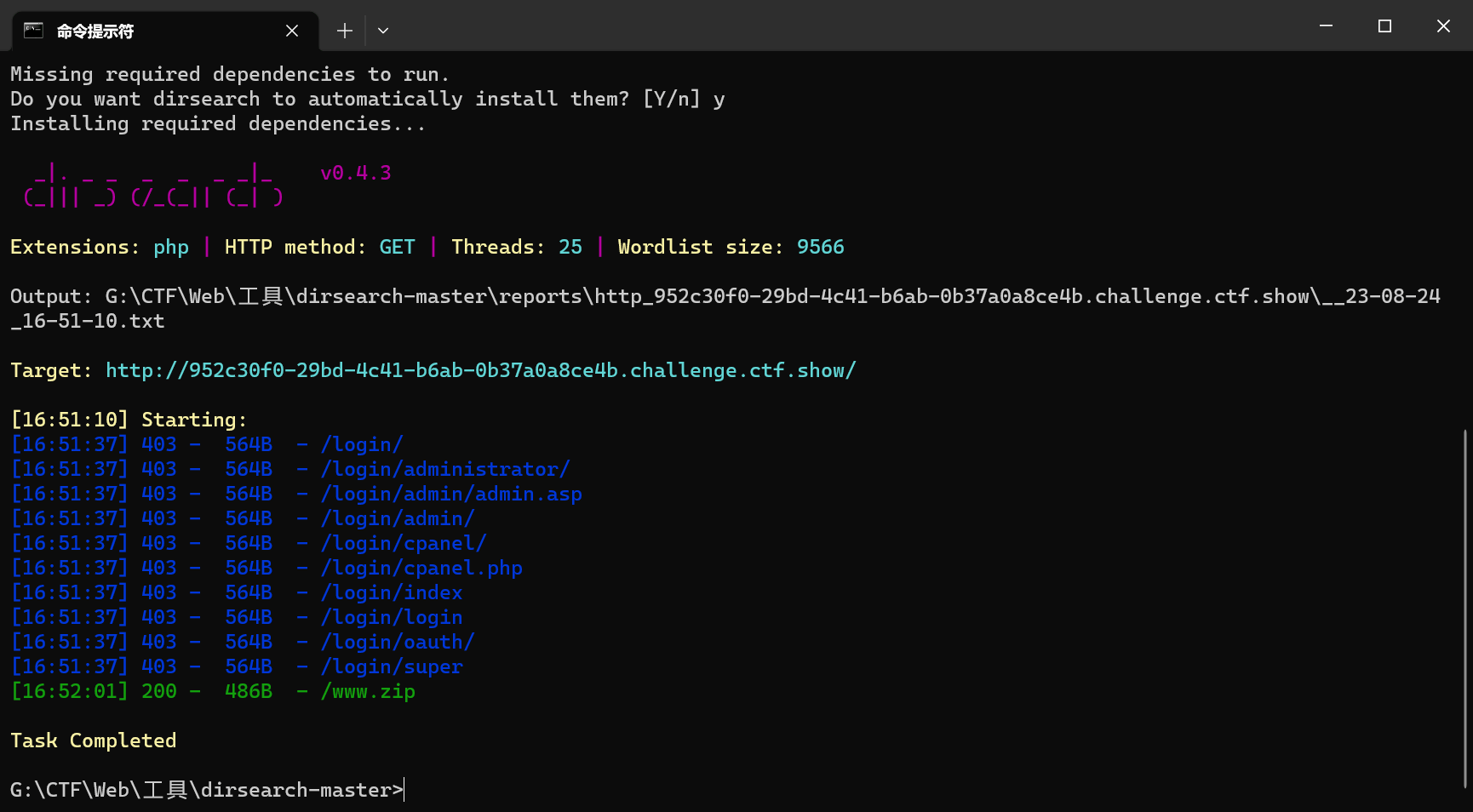
手动在url后添加www.zip
得到备份文件
解压缩后得到flag文件,发现包含的flag格式不符,考虑可能是提示文件名
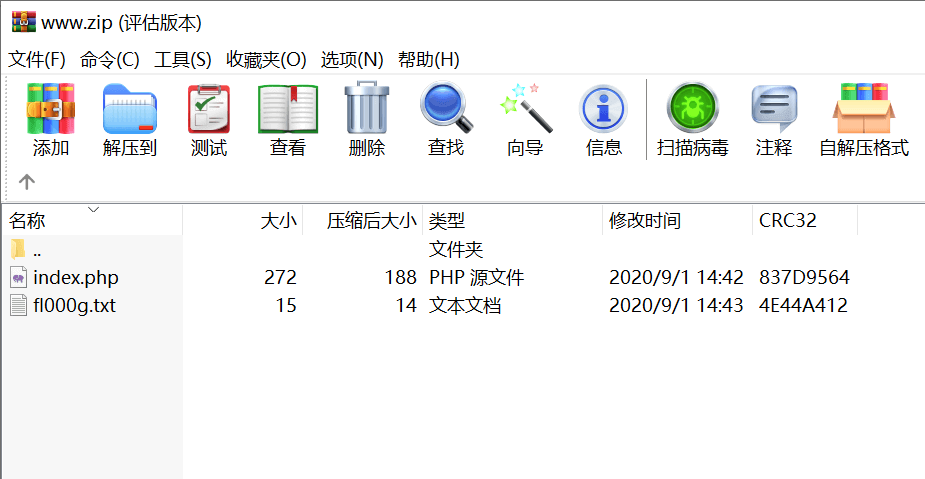
在url后加上fl000g.txt得到最终flag
web7(git泄漏)
使用dirsearch扫描,发现/.git/泄露
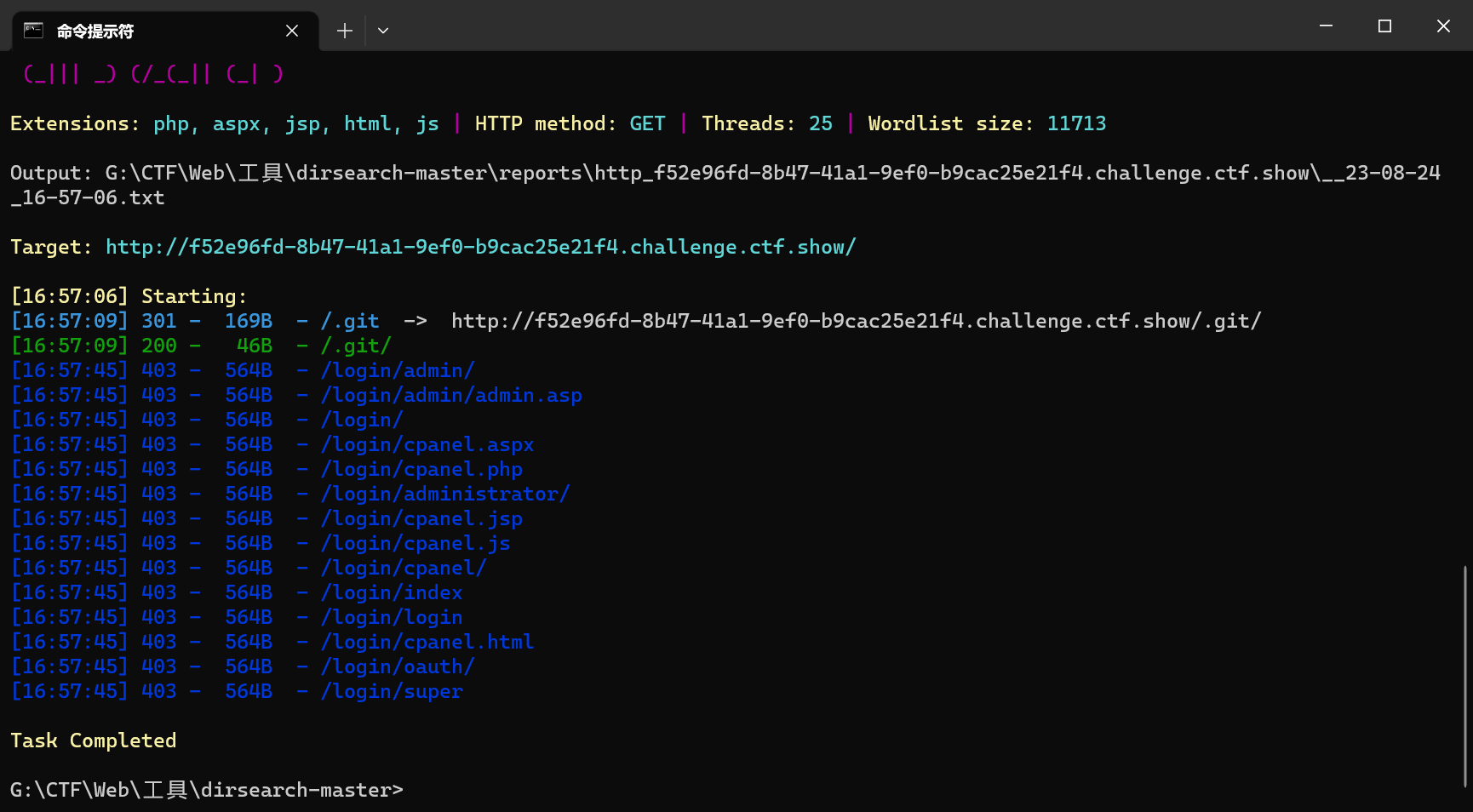
访问该地址后得到flag

web8(svn泄漏)
使用dirsearch扫描,发现/.svn/泄露
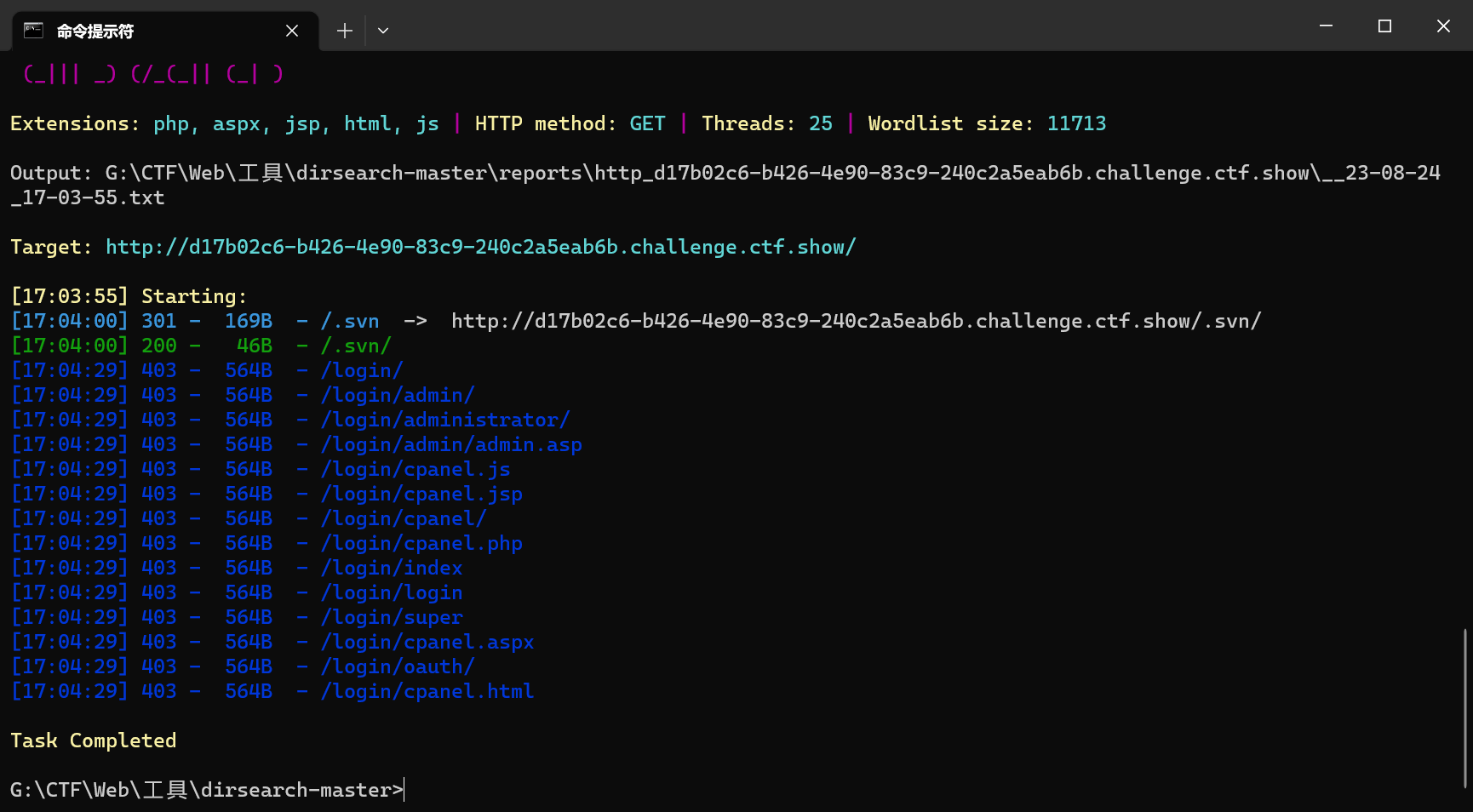
访问该地址后得到flag

web9(vim备份)
使用vim编辑器编写filename文件时,会有一个.filename.swp文件产生,它是隐藏文件。如果编写文件时正常退出,则该swp文件被删除,如果异常退出,该文件则会保存下来,该文件可以用来恢复异常退出时未能保存的文件,同时多次意外退出并不会覆盖旧的.swp文件,而是会生成一个新的,例如.swo文件。
本题的描述显然是暗示考点是Vim泄漏

而需要修改网页,则需要修改index.php文件
尝试访问index.php.swp,下载得到swp文件,打开后得到flag:
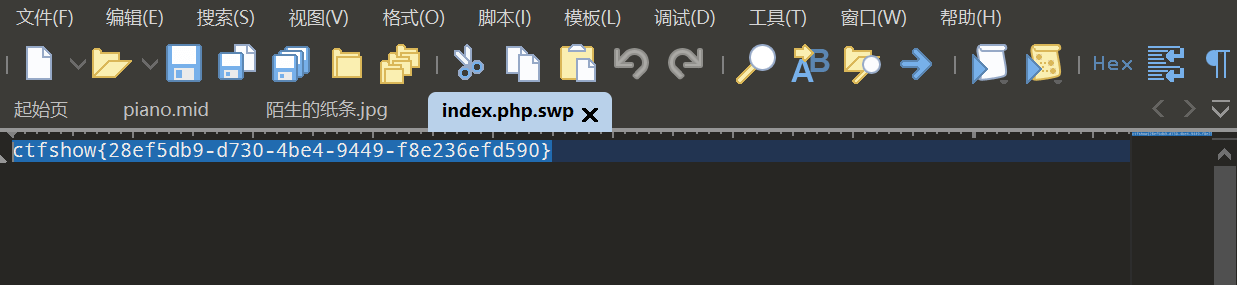
web10(cookie)
查看网页cookie的方式有以下几种:
在浏览器的控制台中输入
javascript:alert(document.cookie),打印 cookie信息以本人使用的edge浏览器为例

点击url栏旁的关于信息,即可查看当前网页使用的Cookie
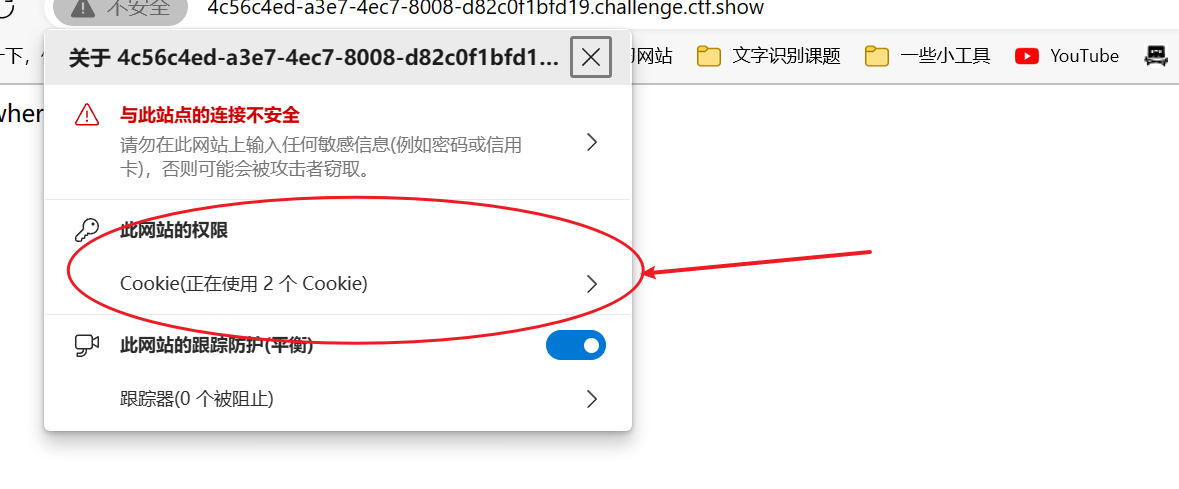
本题直接在控制台打印cookie信息
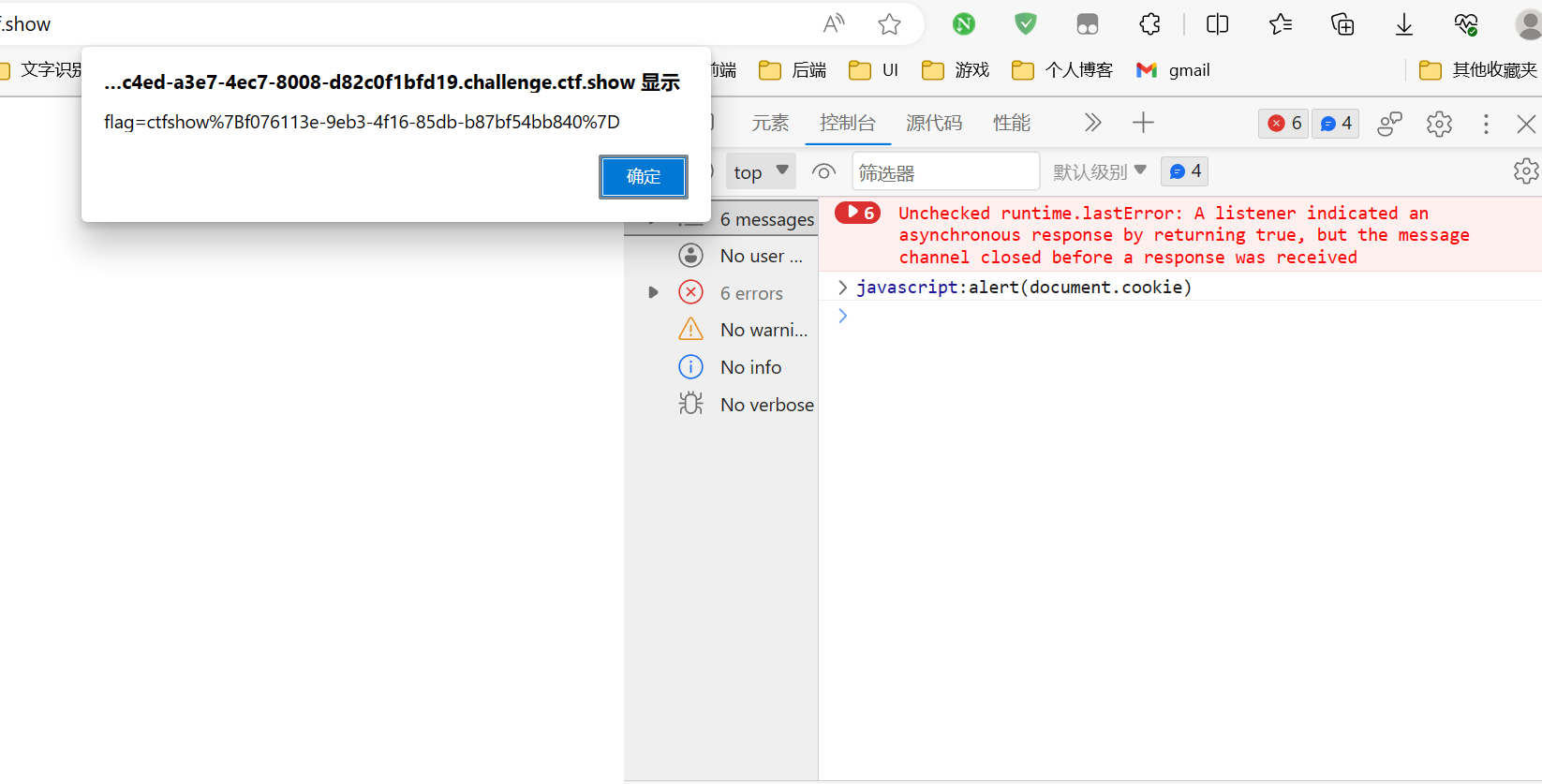
得到flag的url编码
web11(域名解析记录)
本题使用在线工具查询相应站点的域名解析记录
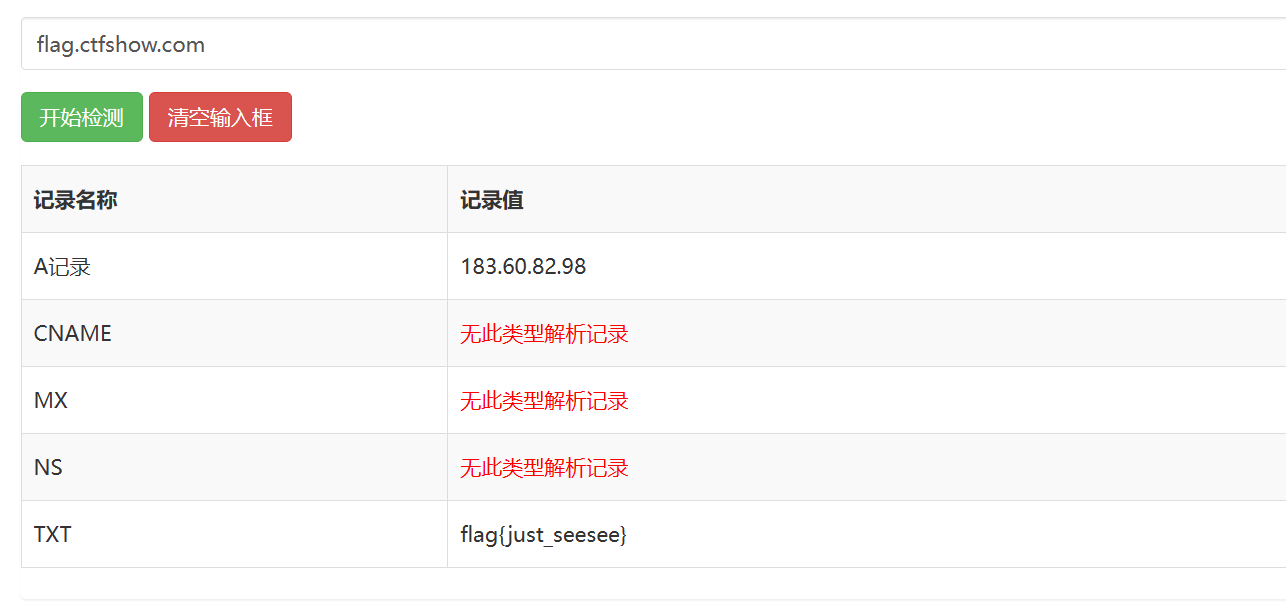
在TXT记录中得到flag
web12(社工)
用dirsearch扫到admin这个目录,应该是有登录界面
根据题目提示,密码应该就藏在页面当中
尝试页面下方的电话号码
成功登录
web13(技术文档)
页面底部留有技术文档document
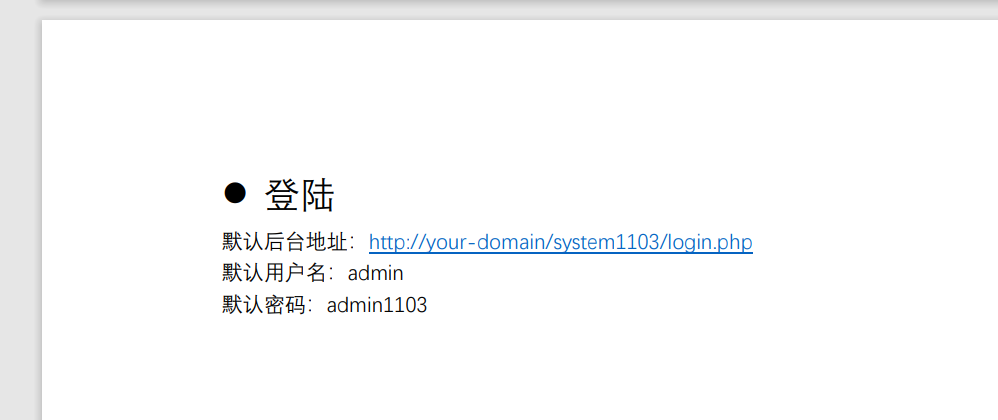
按照指示登录http://http://f78fddce-9ace-4612-a3d3-82c302c63f6e.challenge.ctf.show/system1103/login.php得到flag
web14(网页编辑功能泄漏)
用dirsearch扫出editor目录
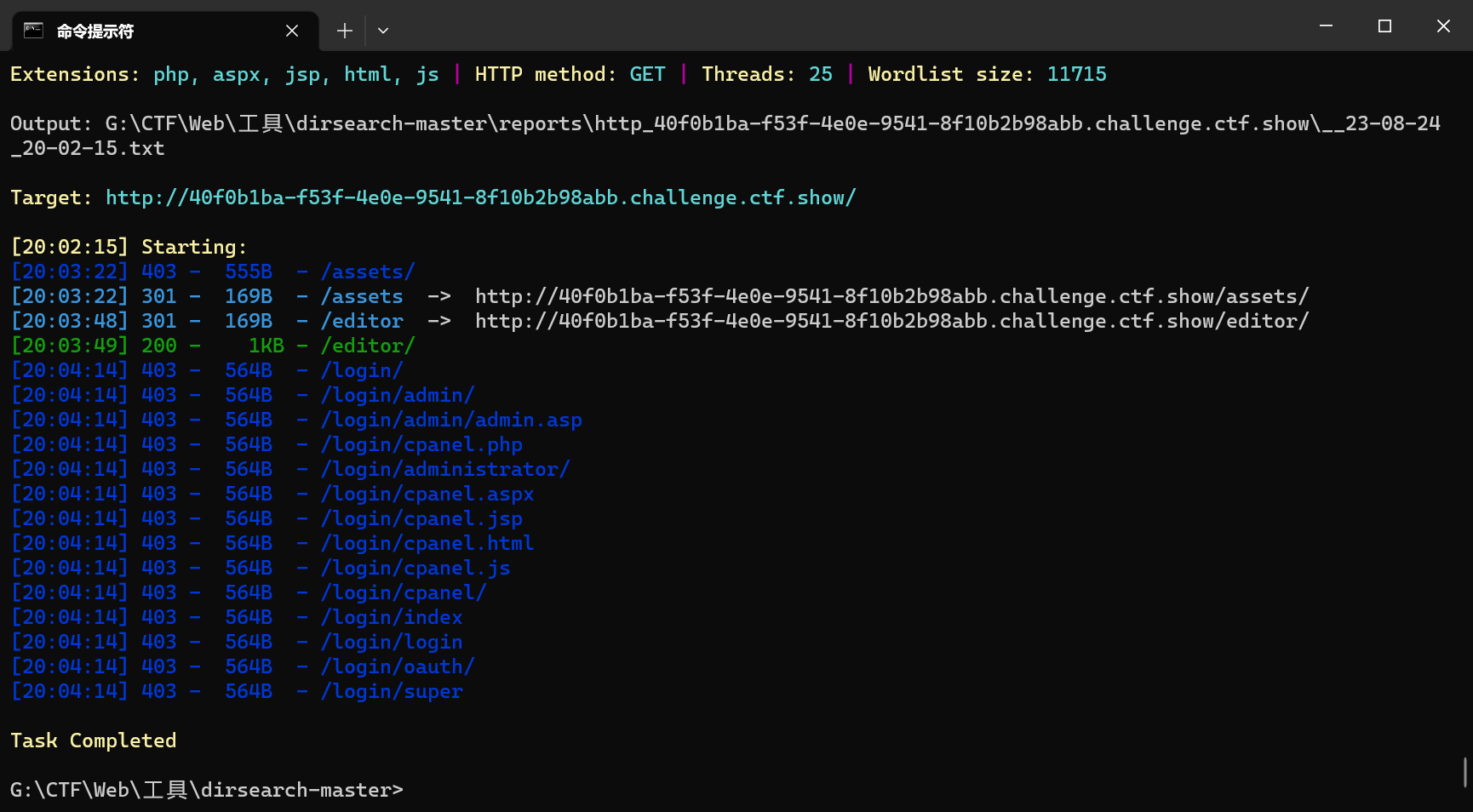
访问editor,进入一个提交页面
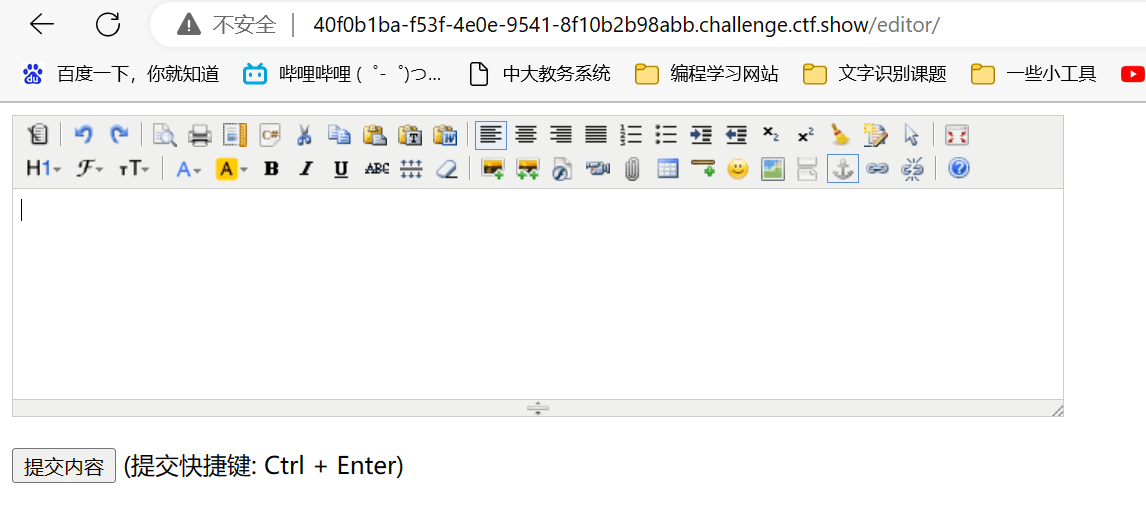
发现有插入文件的功能,那我们就可以直接服务器上的文件了
linux下的特殊目录:/var/www/html,把静态网页文件放到这个目录下就可以通过IP很方便的访问,
如果要访问 /var/www/html/myfolder/test.html
我在浏览器地址栏输入 http://[ip]/myfolder/test.html就行了。
不过这个便利的功能并不是linux操作系统自带的,需要启用httpd服务才行。
猜测本题的网页在var文件夹下
顺利按/var/www/html的路径找到源代码
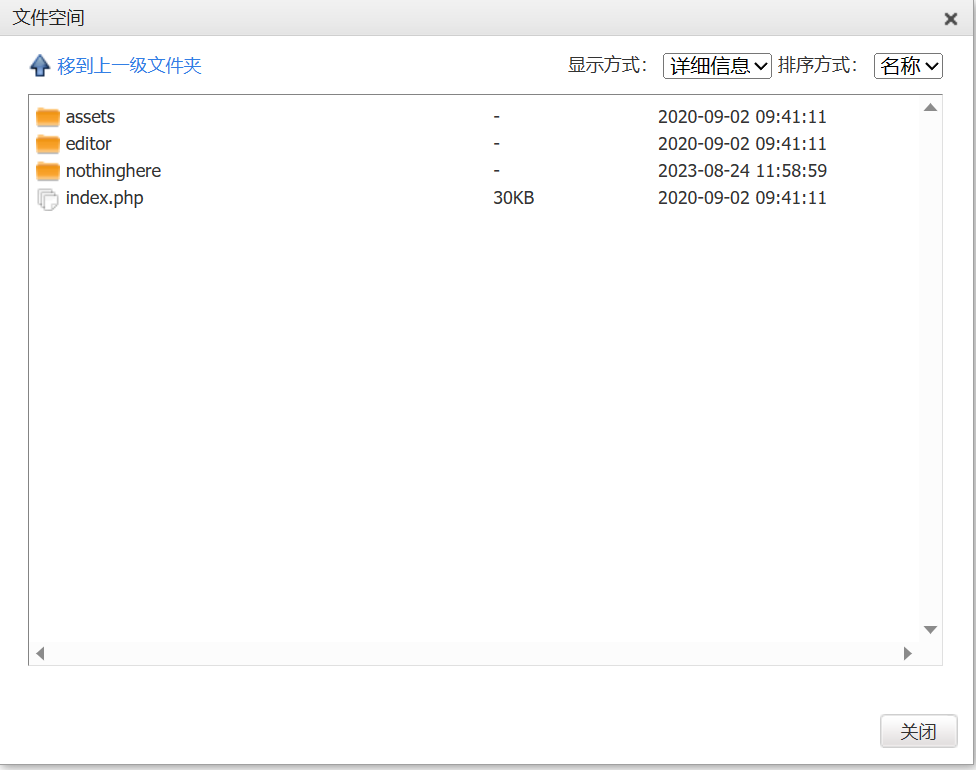
在nothinghere下找到flag
web15(社工)
用dirsearch扫完发现存在管理员登录入口
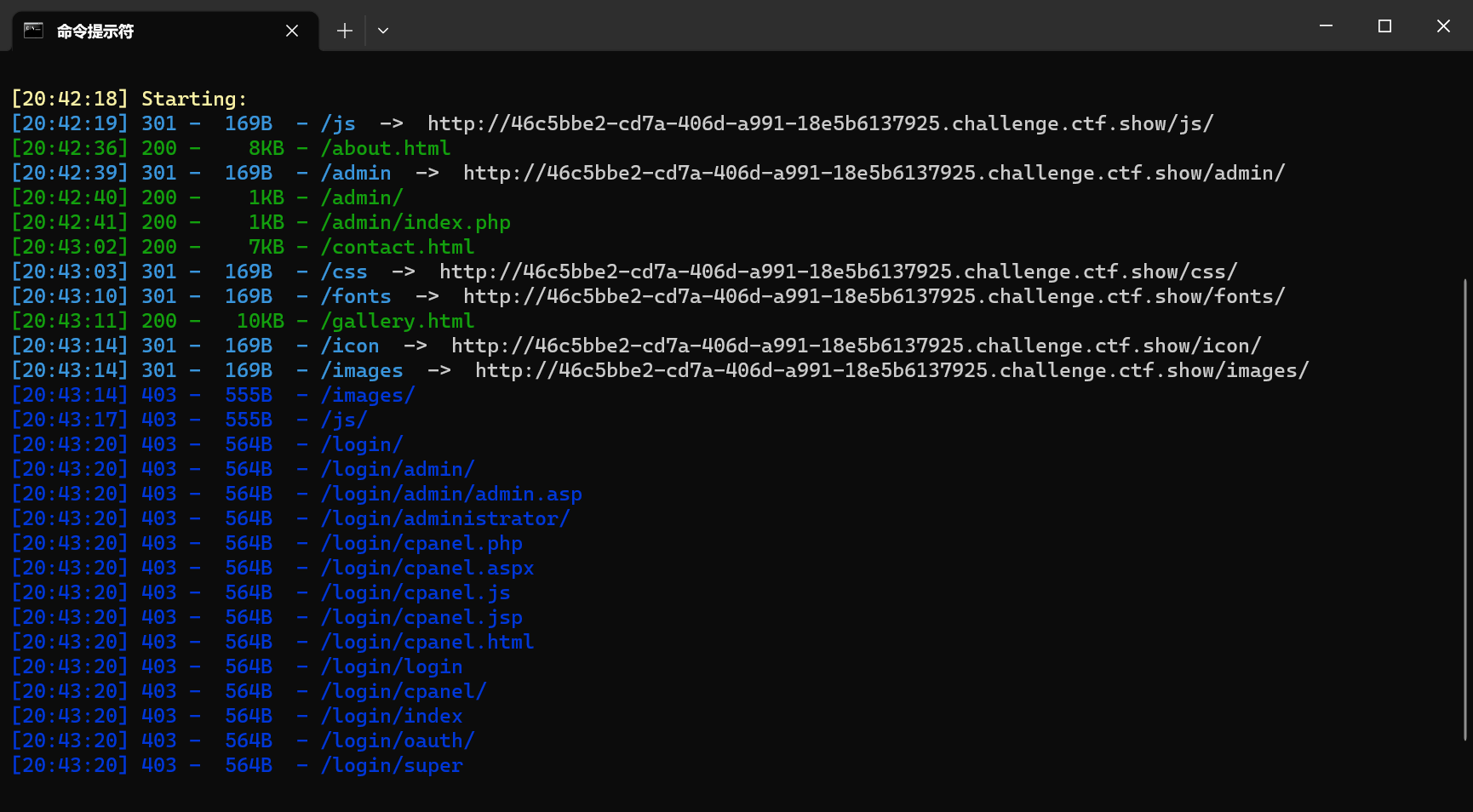
该后台登录系统存在忘记密码功能
同时页面底部也泄露了具体邮箱
第一个问题是在哪个城市

搜索QQ号,通过QQ上的资料确定所在地在西安
提交后显示密码已重置

重新登录并得到flag
web16(php探针)
根据题目的提示,网站应该是遗留了php探针
经过尝试成功访问/tz.php
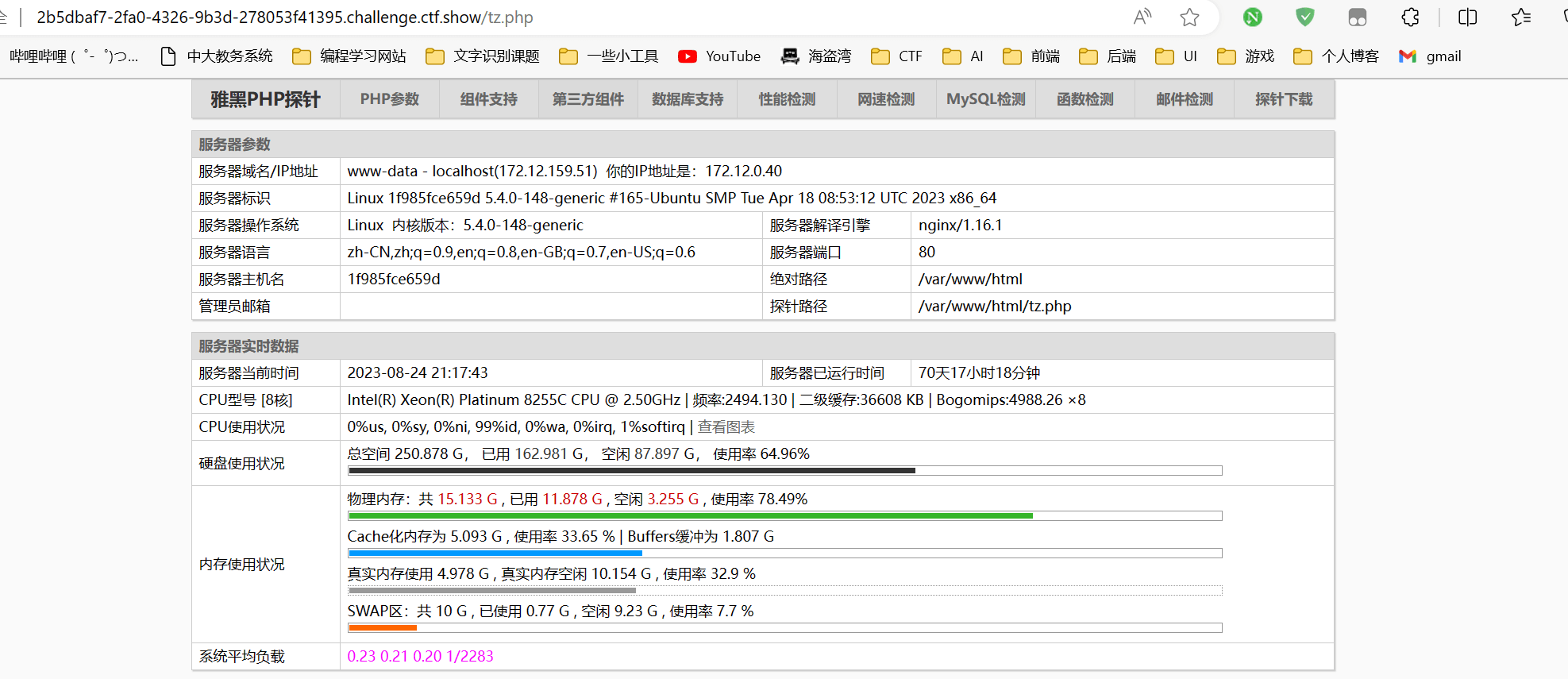
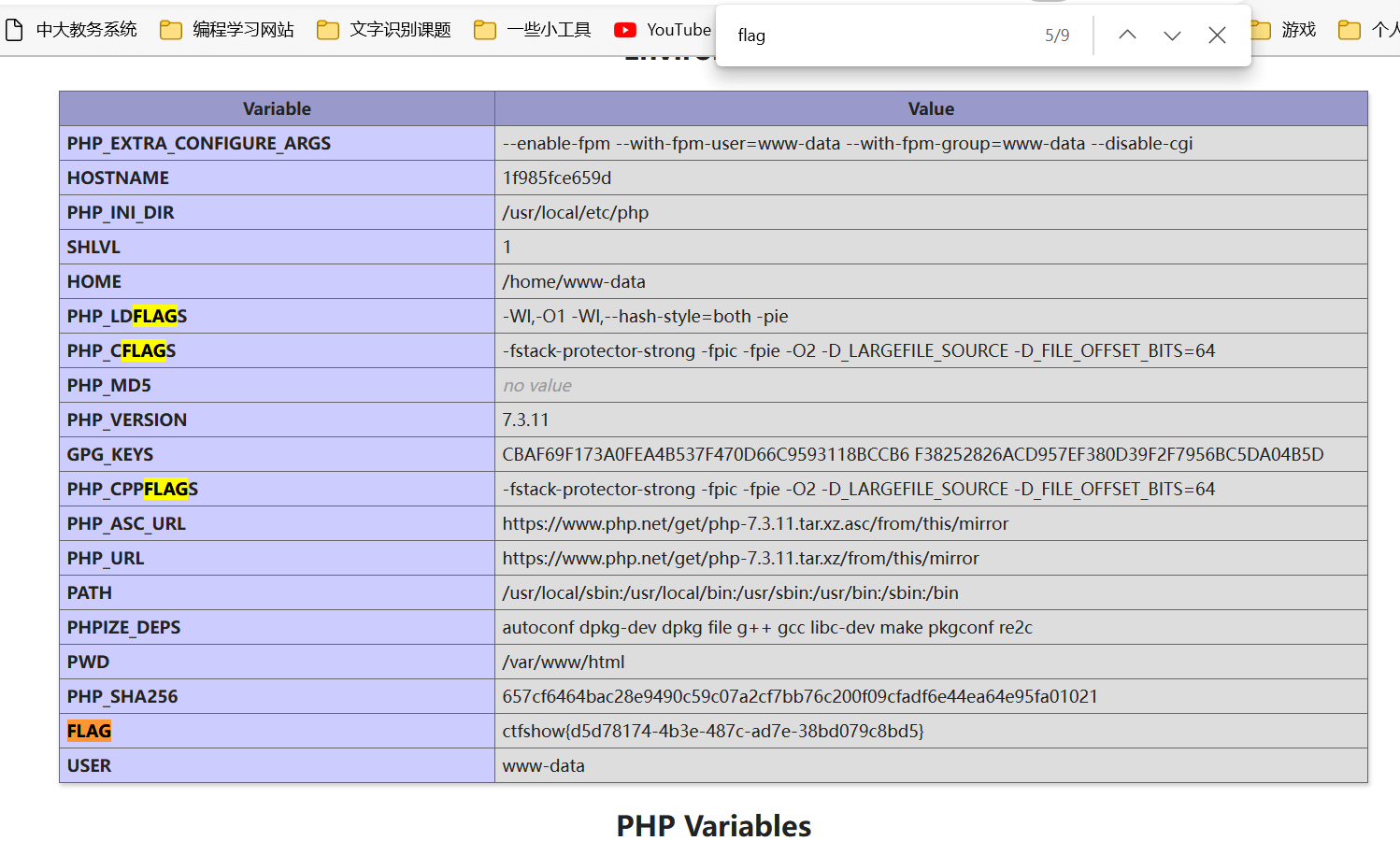
发现phpinfo处是灰色链接,点击进入phpinfo
查找flag属性并找到flag
web17(sql备份)
用dirsearch扫出sql备份文件
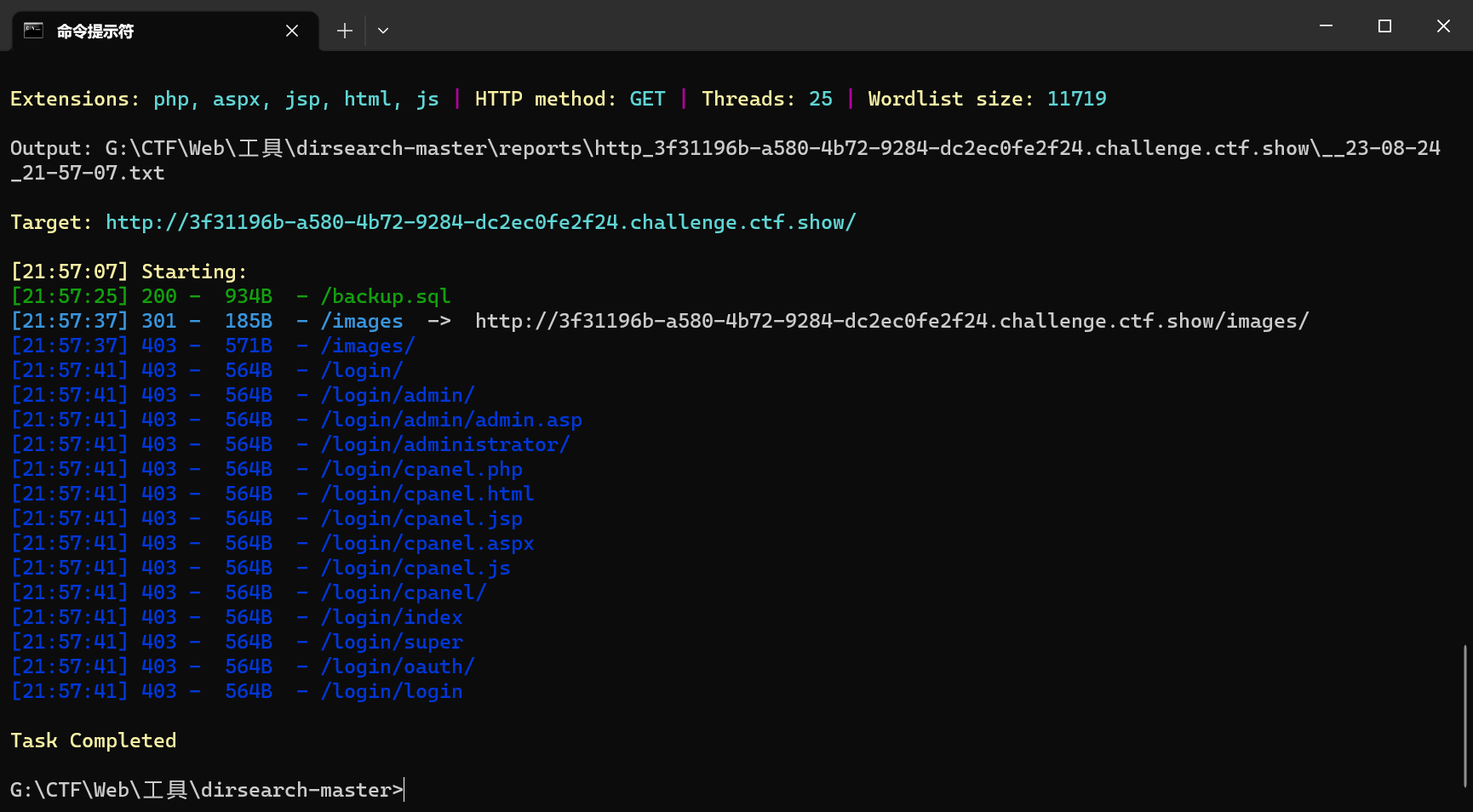
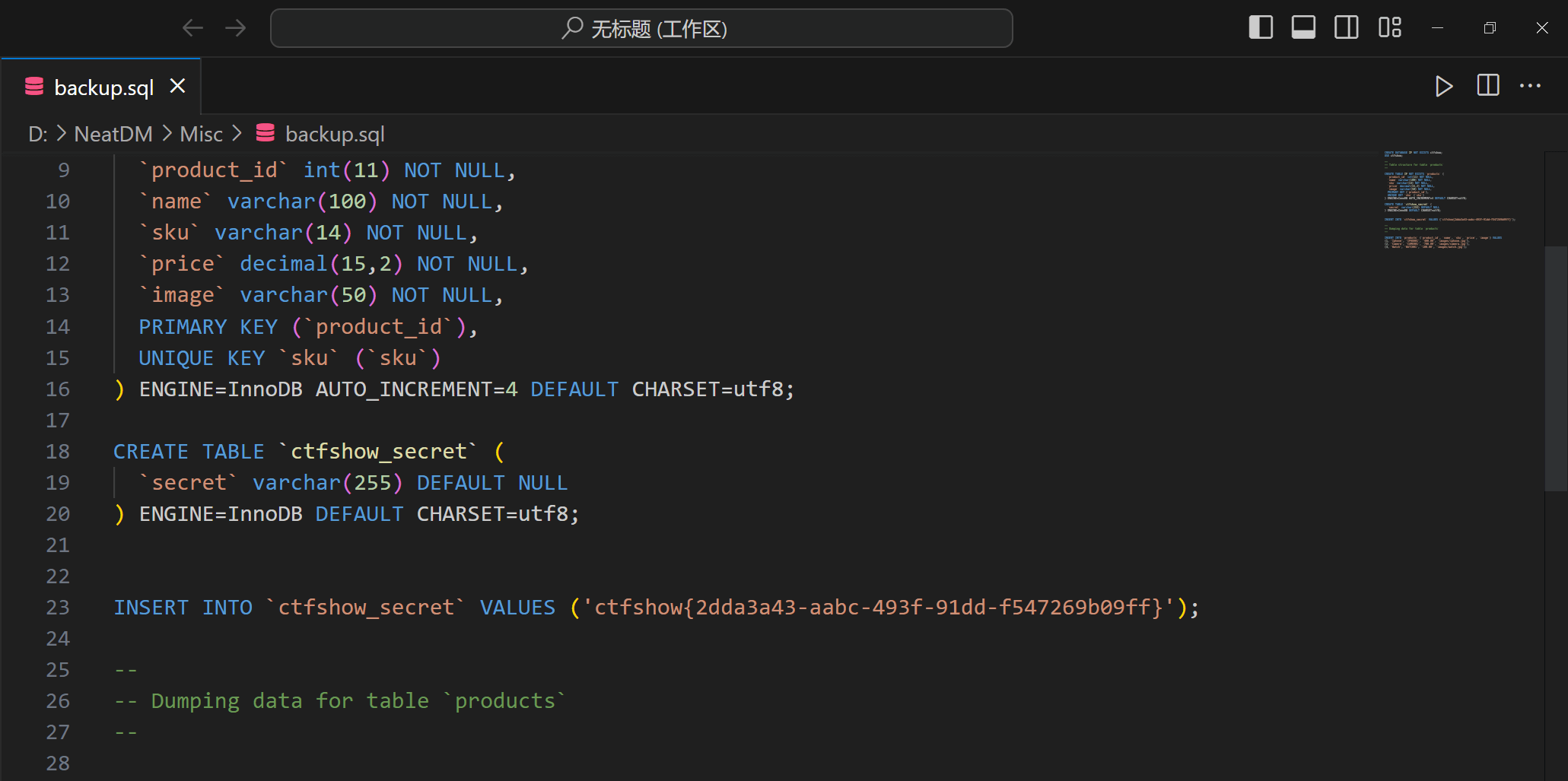
下载后打开,找到flag
web18(查阅js源码)
看到这种游戏类型的题目,大概率是不能手动过关的,只能从修改规则上入手
打开js源码,找到游戏过关相关的代码
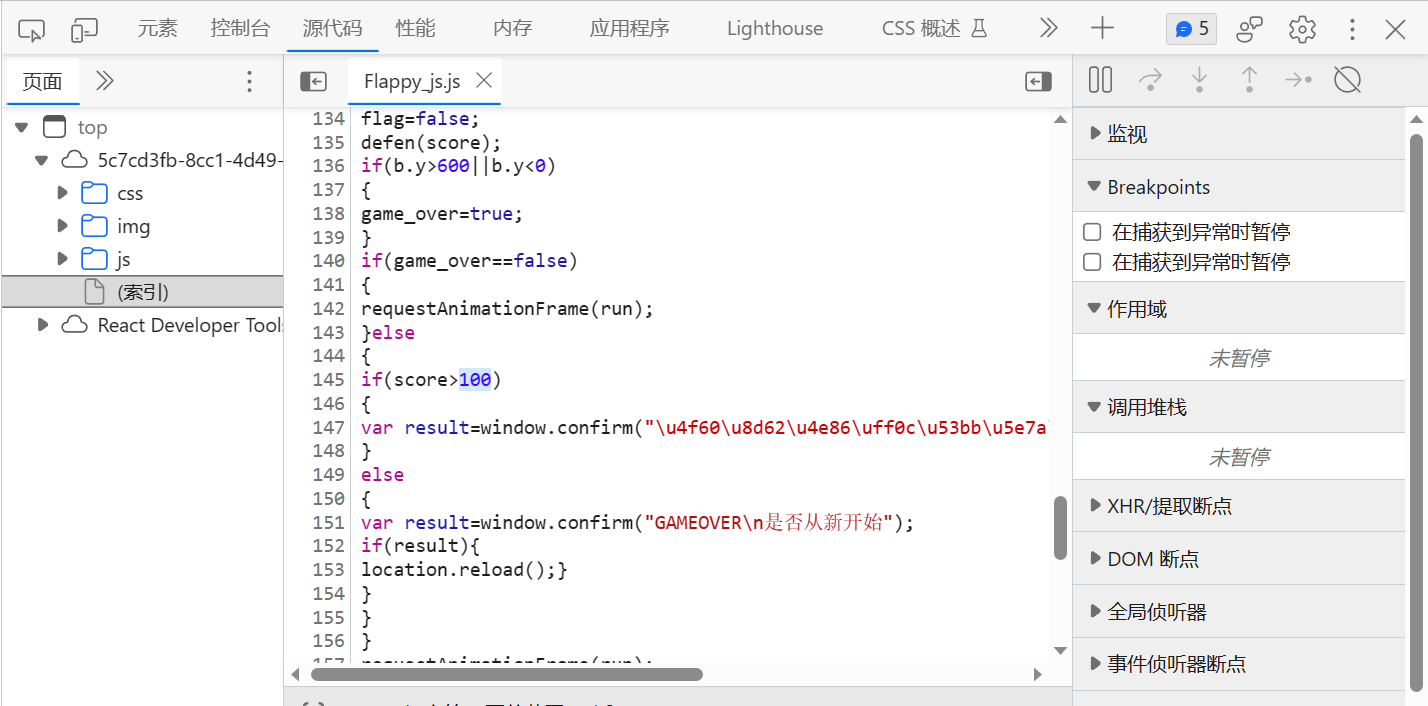
发现如果达到100分,会弹窗一段Unicode编码
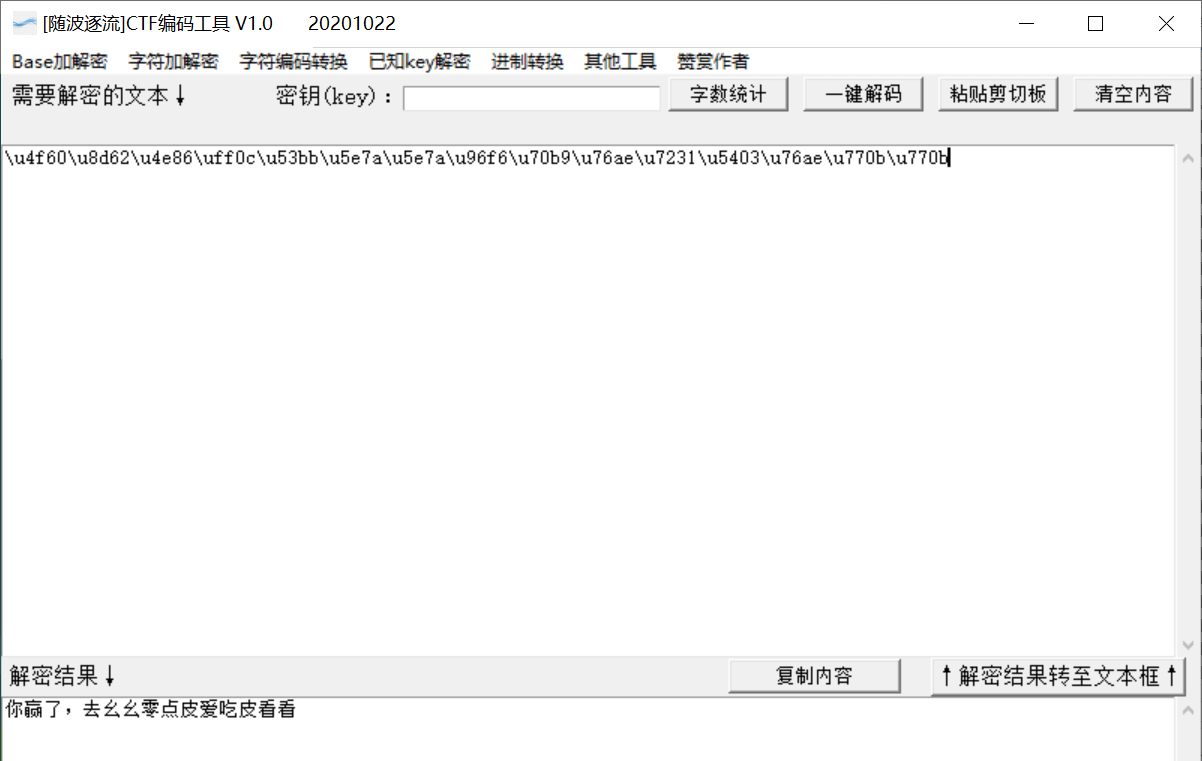
解码后得到你赢了,去幺幺零点皮爱吃皮看看
在url后加上/110.php得到flag
web19(密码泄露)
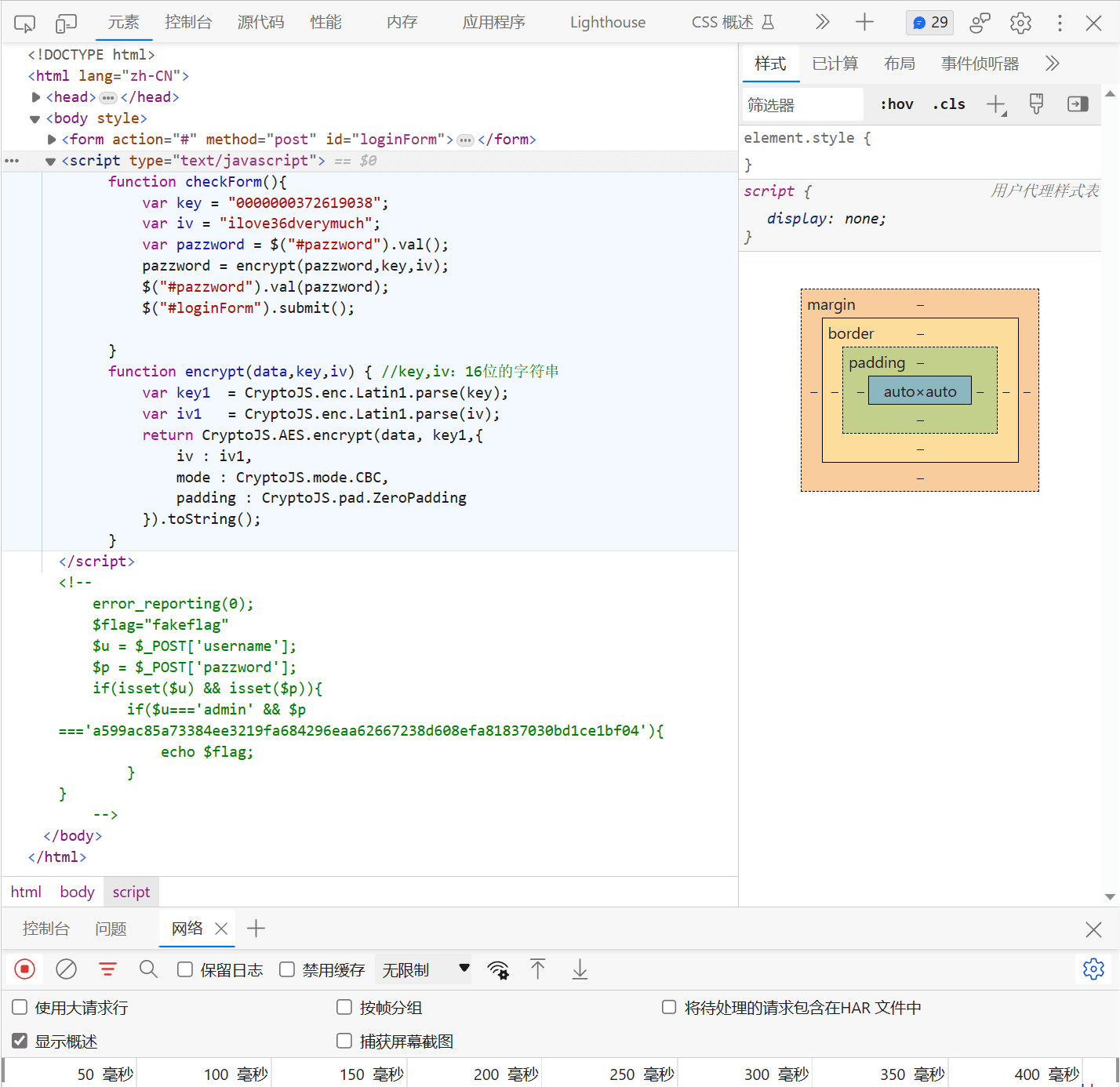
分享加密原理后,解密注释中泄漏的密文
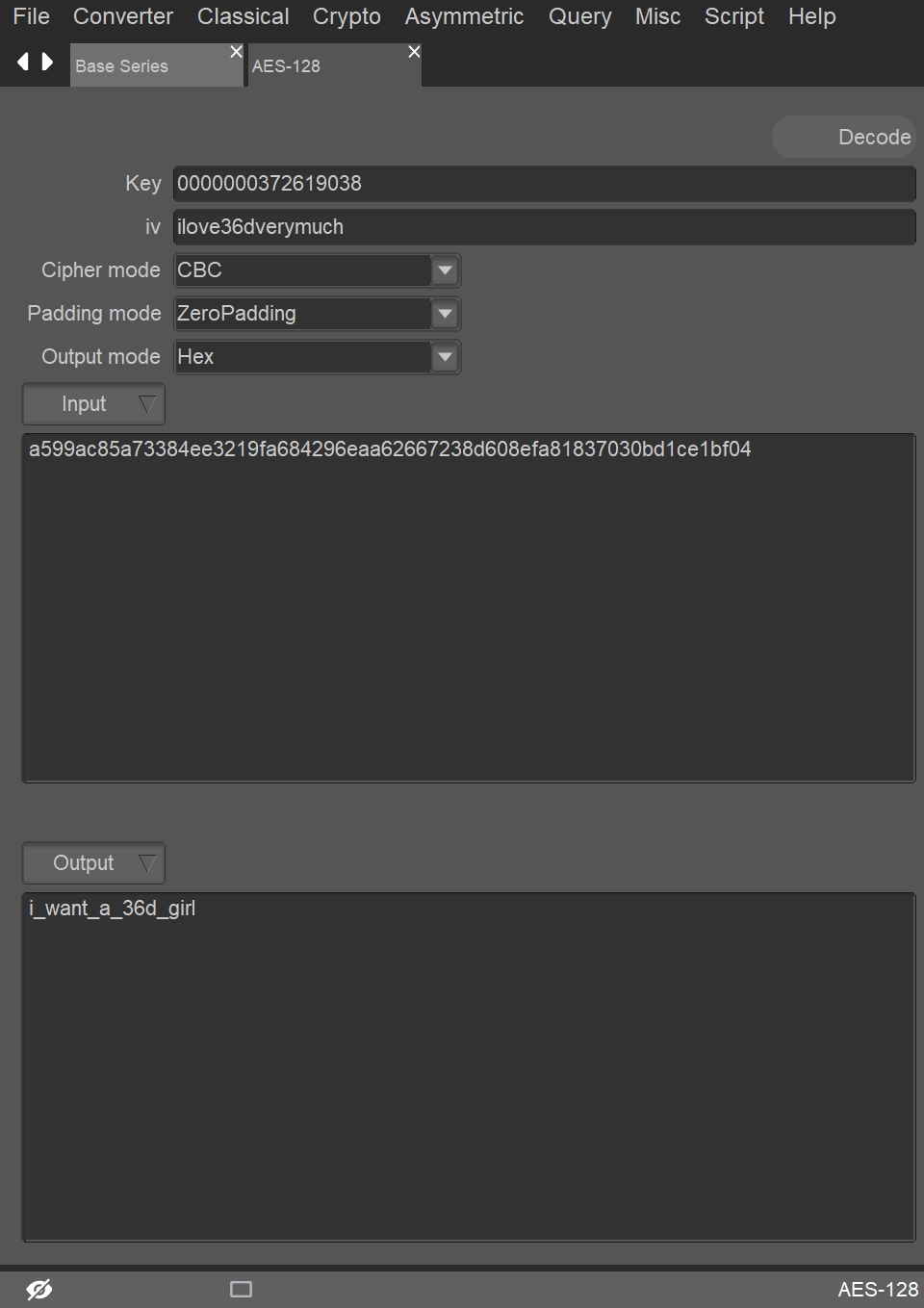
使用其登录后成功获得flag
web20(mdb泄漏)
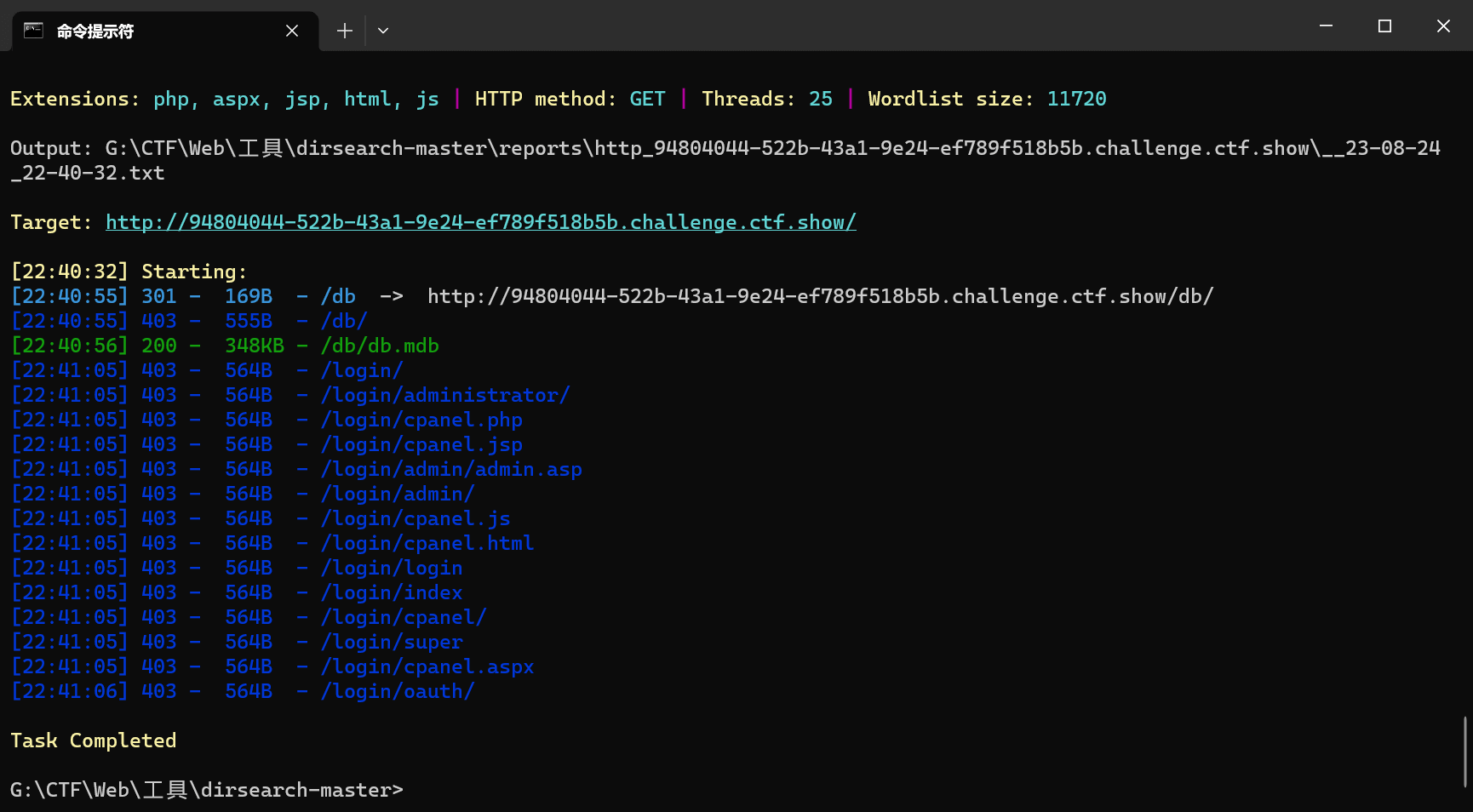
扫出/db/db.mdb数据库文件
下载后使用记事本打开并查找flag
从0到1
常见的搜集(robots、vim、gedit)
尝试常规的信息收集方法
首先是robots.txt
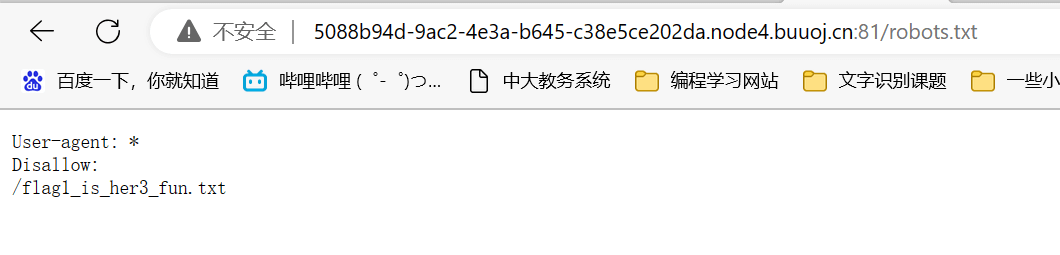
得到flag目录
获得flag1前半段n1book{info_1
测试是否存在vim备份文件,尝试/.index.php.swp
下载得到_index.php.swp文件
其中有后半段flagp0rtant_hack}
测试是否存在gedit备份文件,尝试/index.php~
得到flag中段s_v3ry_im
粗心的小李(git泄漏)
题目提示git泄漏,考虑git泄露时的三种场景
首先是常规git泄漏
使用GitHacker恢复源码
githacker --url http://2f16f0e7-c2bf-4ca1-95dd-37e0cf03bd0a.node4.buuoj.cn:81/.git/ --output-folder G:\CTF\Web\工具\GitHacker\result
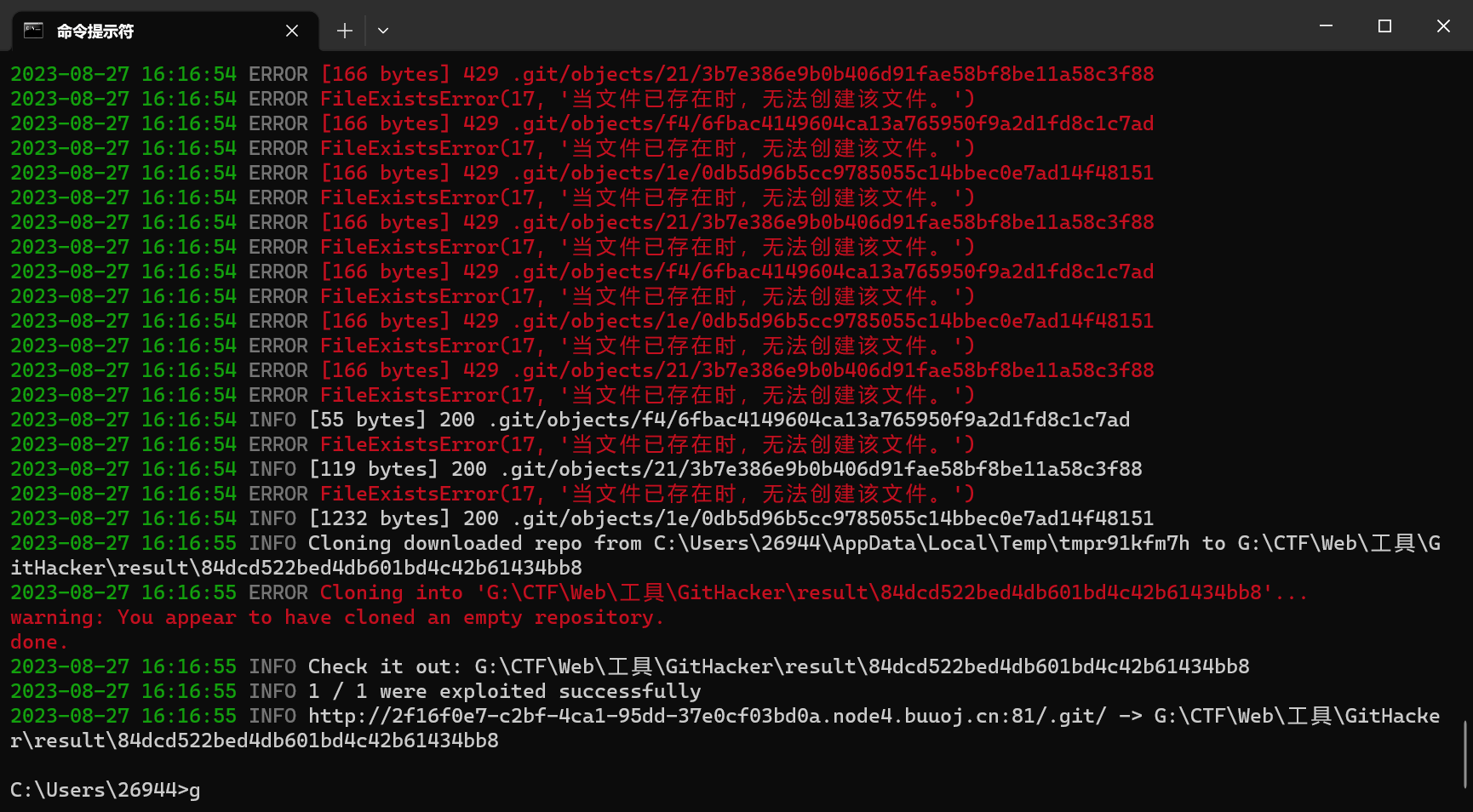
得到源码index.html
打开后得到flag
CTFHUB 信息泄漏
目录遍历
点击开始寻找flag,发现嵌套了非常多层目录
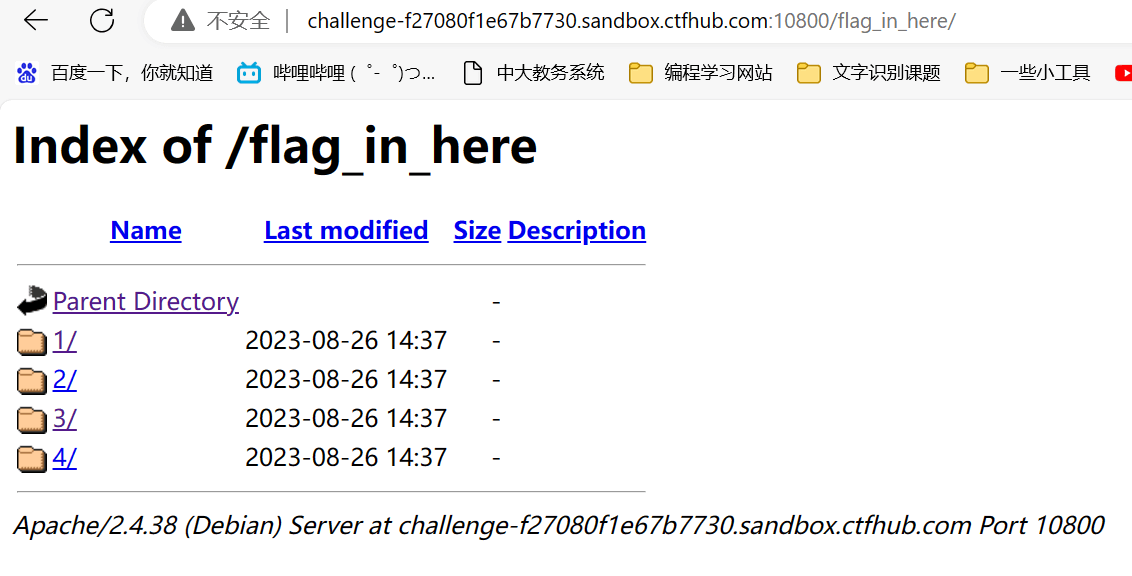
将flag_in_here添加到爆破字典中
使用dirsearch进行递归目录扫描,设置最多3层:python dirsearch.py -u http://challenge-f27080f1e67b7730.sandbox.ctfhub.com:10800 -i 200,300-399 -r -R 3
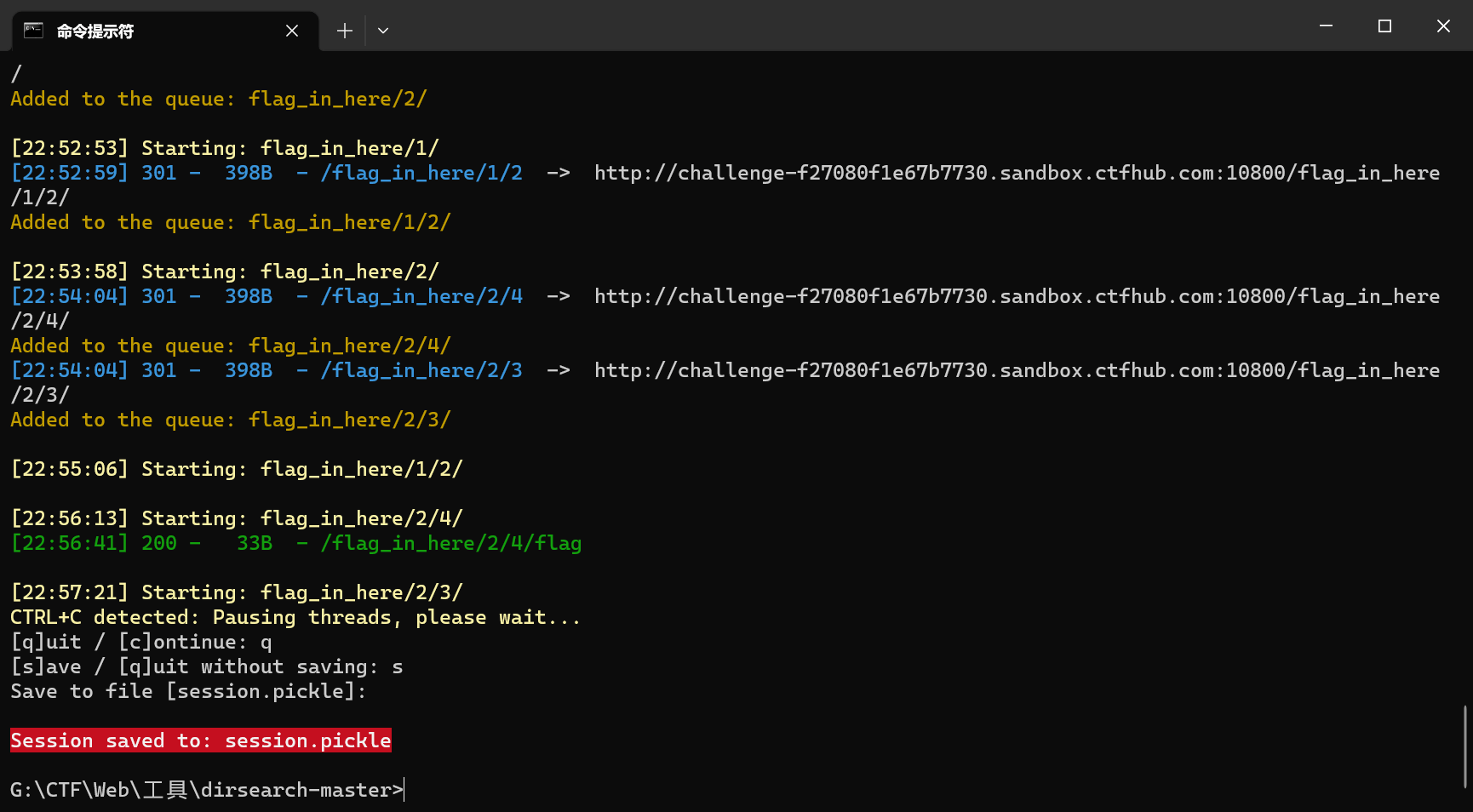
扫到flag文件,访问/flag_in_here/2/4/flag

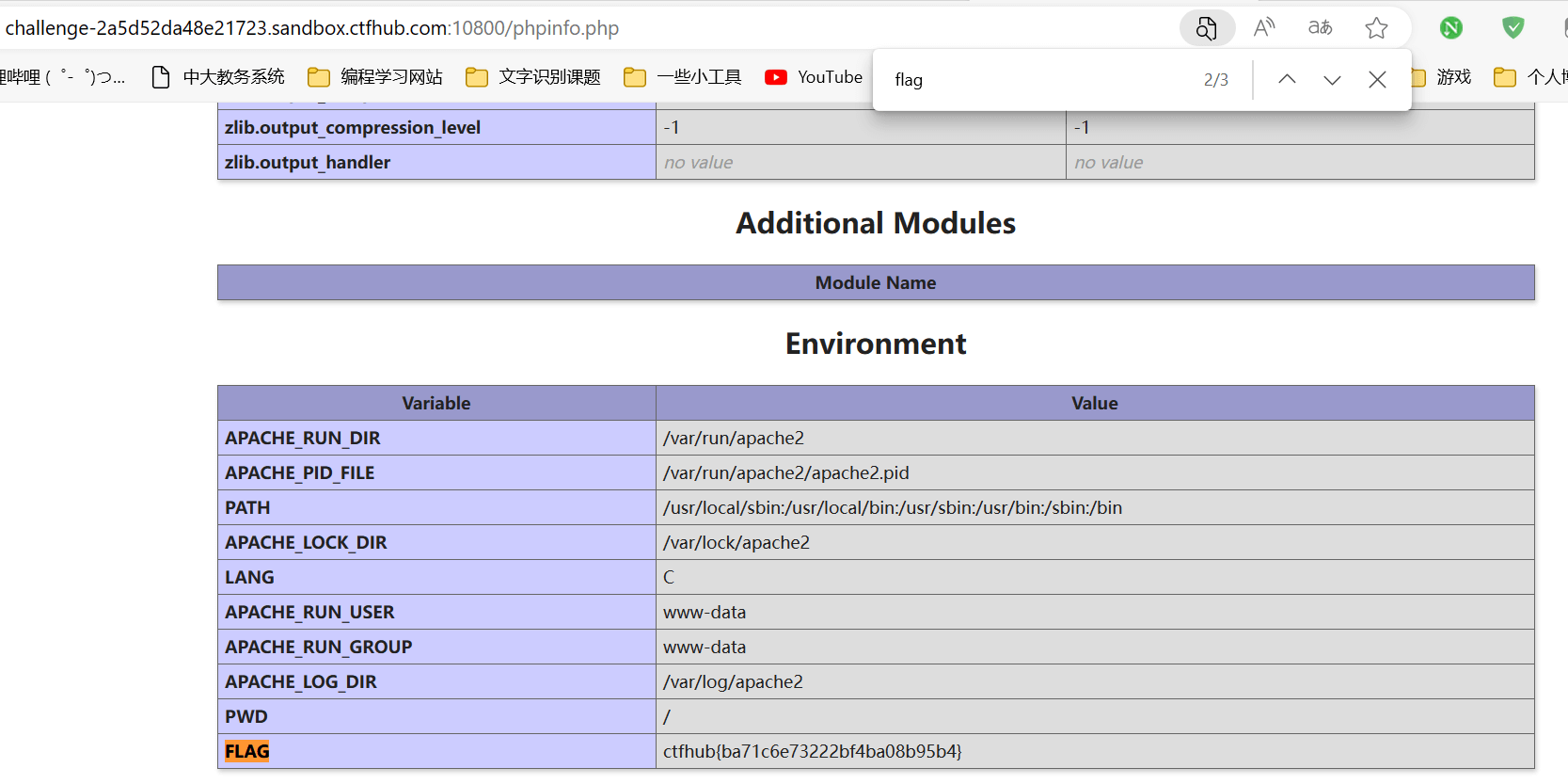
PHPINFO
点击查看phpinfo,查找flag
备份文件下载
网站源码
使用自定义脚本扫描备份文件
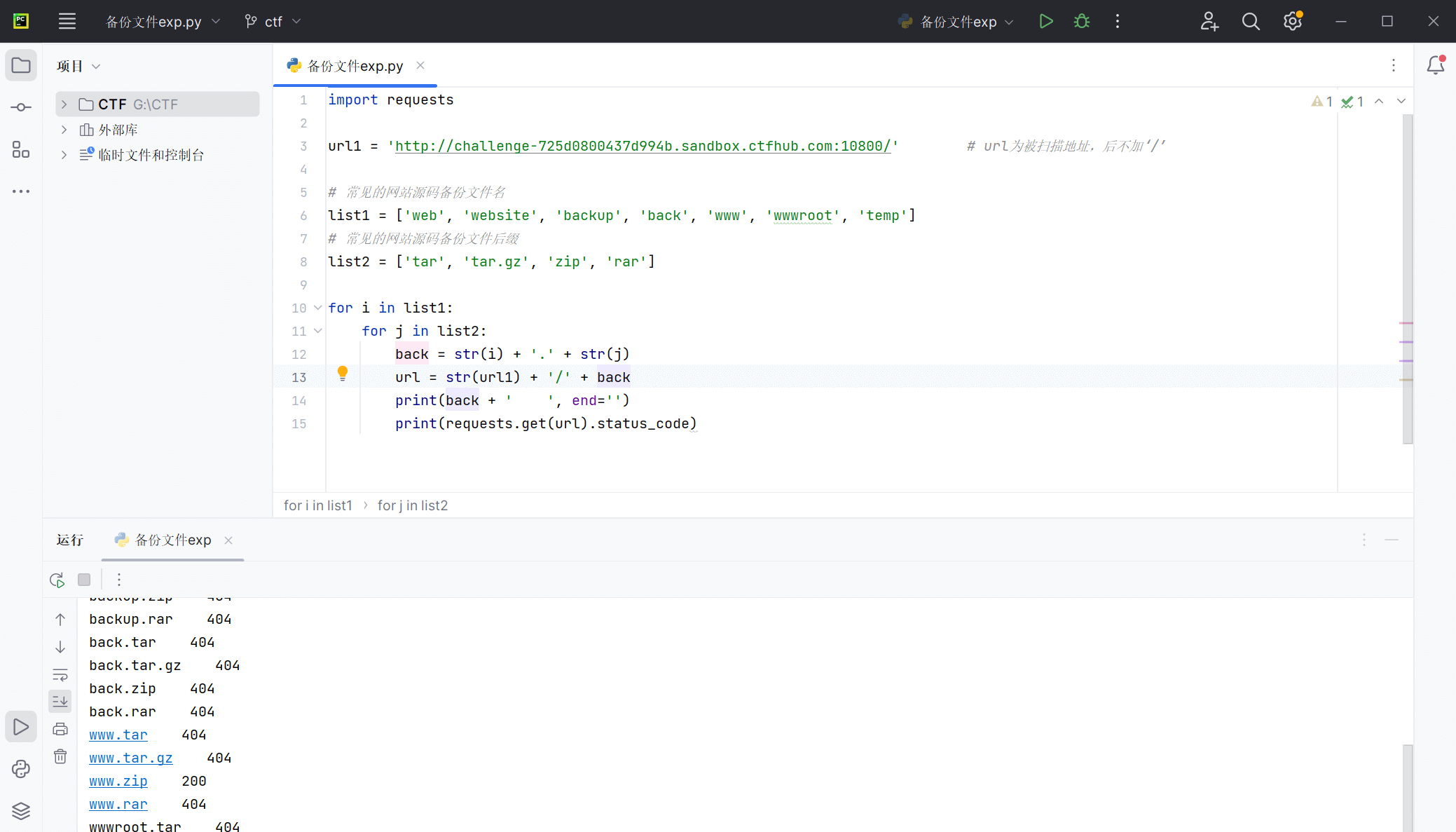
下载www.zip,解压后得到如下文件
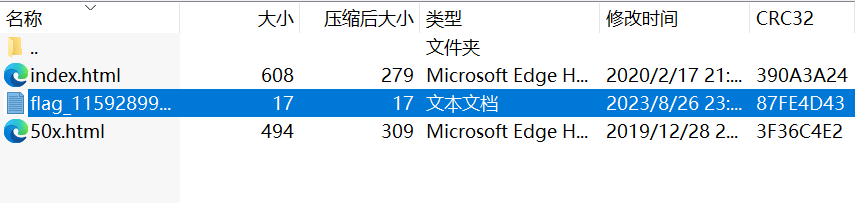
txt中显示where is flag ??
尝试在url添加/flag_115928996.txt,得到flag

bak文件
使用自定义脚本扫描得到index.php.bak
下载后得到flag
vim缓存
参考vim泄漏原理,在url后加上/.index.php.swp
下载备份文件后得到flag
.DS_Store
在url后加上/.DS_Store,下载得到备份文件
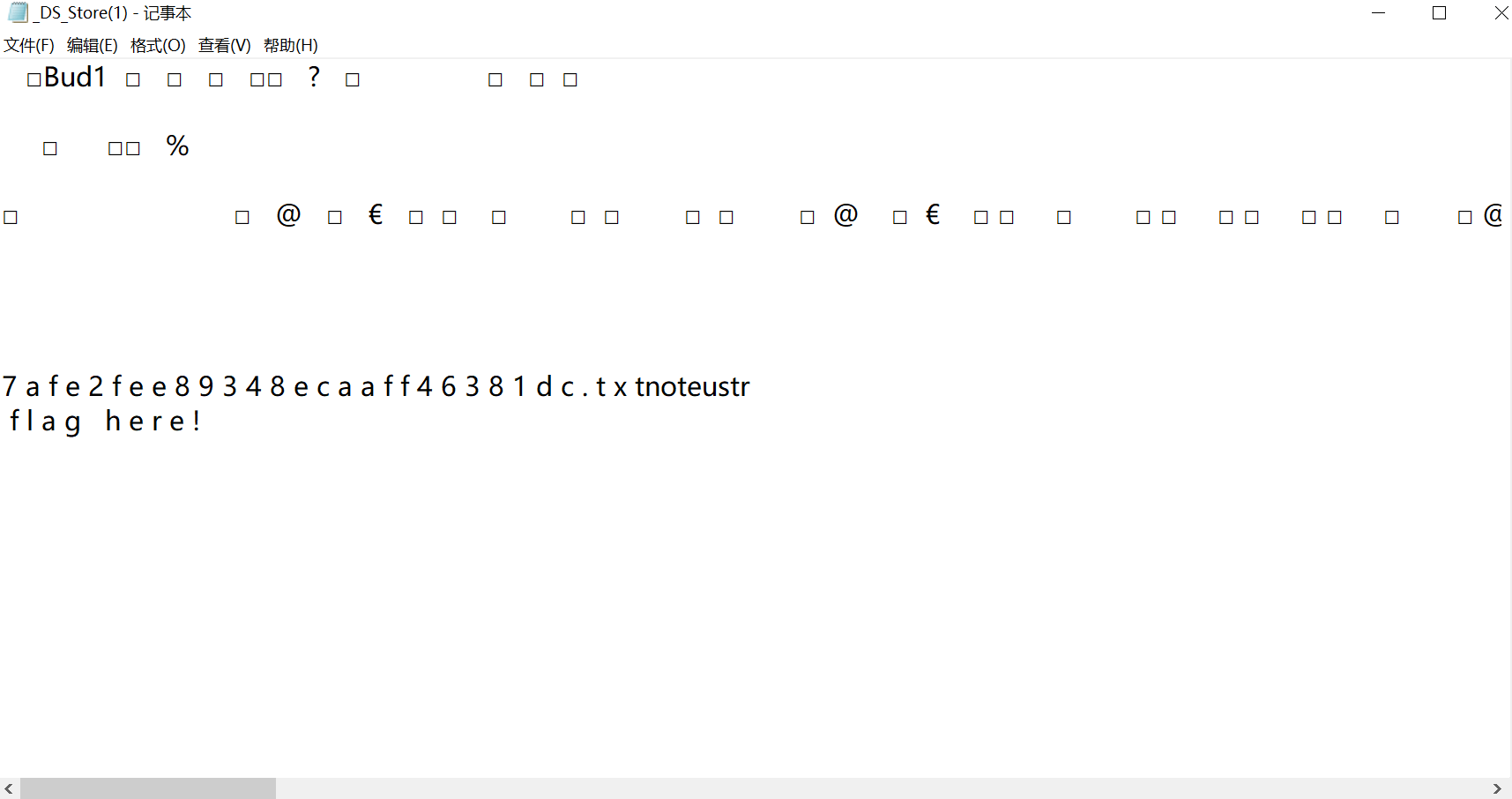
根据提示在url后加上/1626d67afe2fee89348ecaaff46381dc.txt得到flag
Git泄漏
Log
使用GitHacker扫描站点的.git文件,生成源码
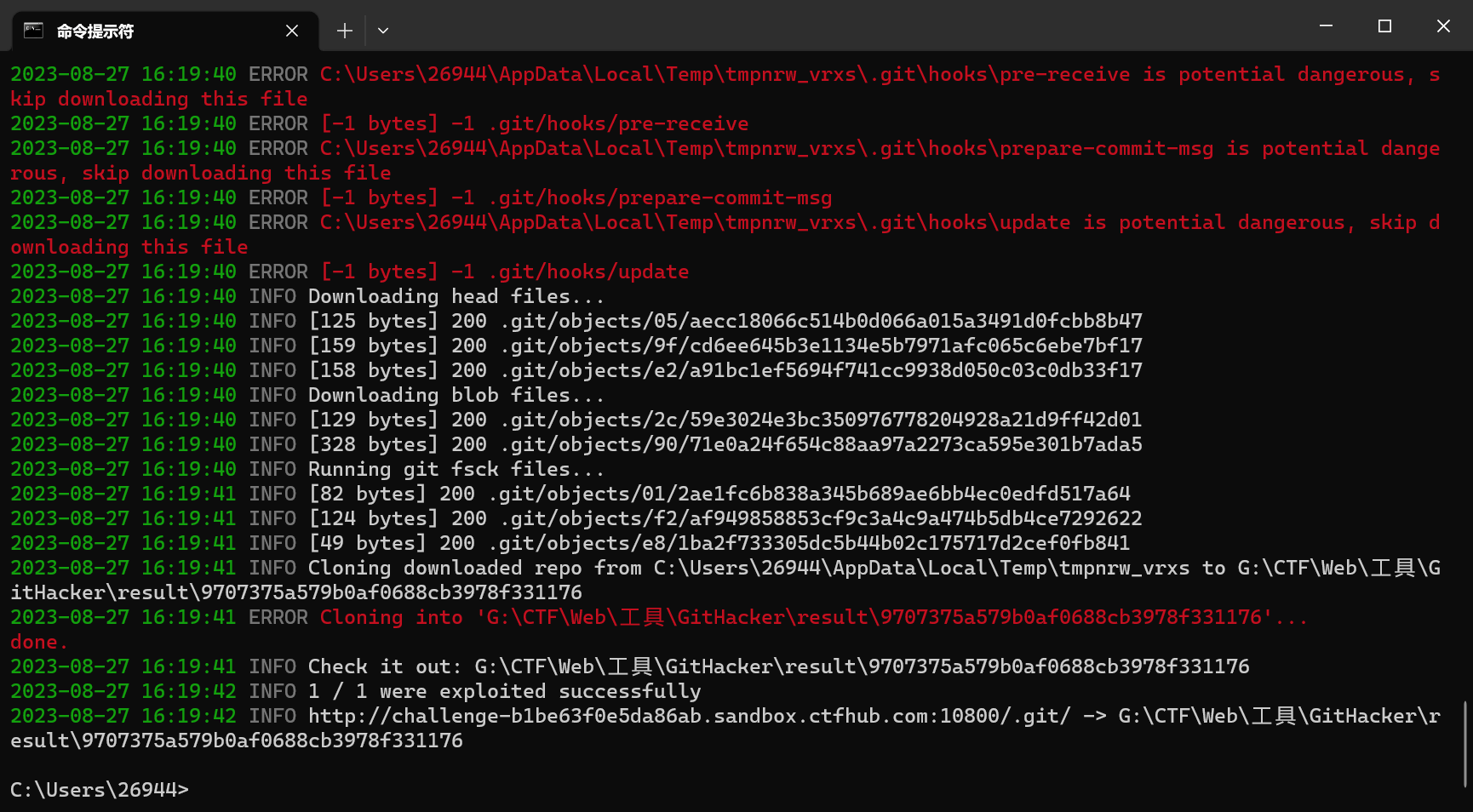
源代码目录如下
50x.html界面提示log日志

执行git log命令
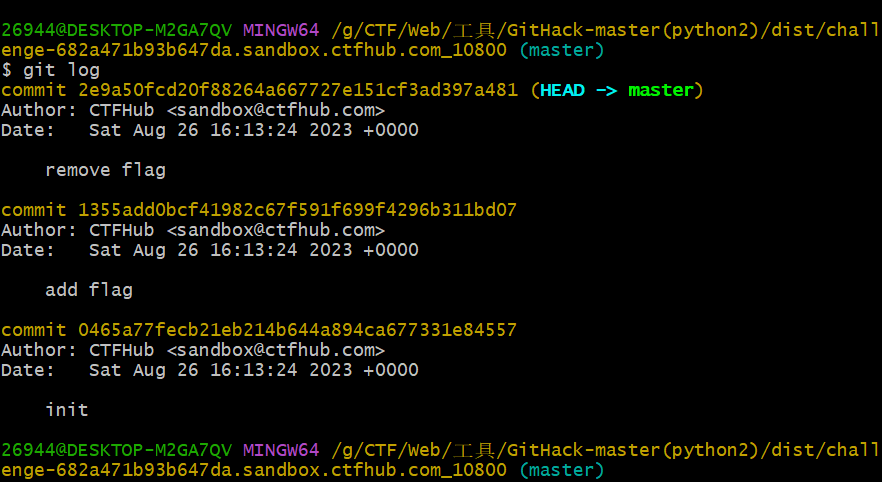
使用git diff 1355add0bcf41982c67f591f699f4296b311bd07进行回滚
得到flag
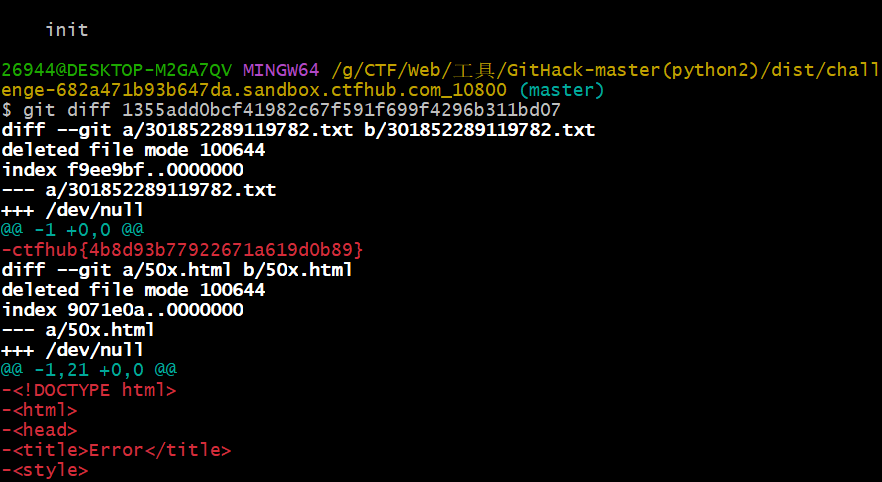
Stash
使用GitHacker恢复源码githacker --url http://challenge-ceb412434853a026.sandbox.ctfhub.com:10800/.git/ --output-folder G:\CTF\Web\工具\GitHacker\result
得到源码目录如下
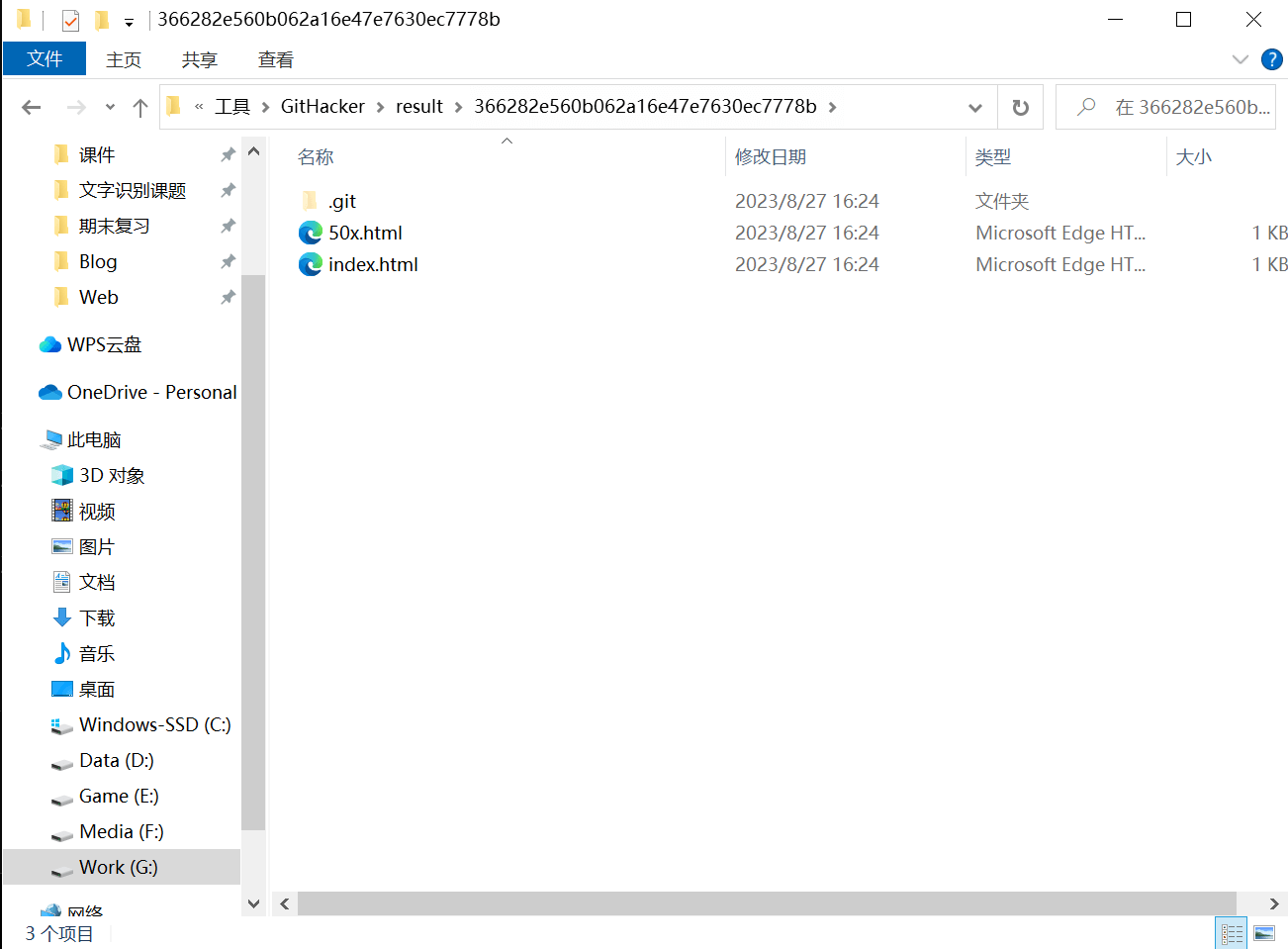
执行git log查看版本
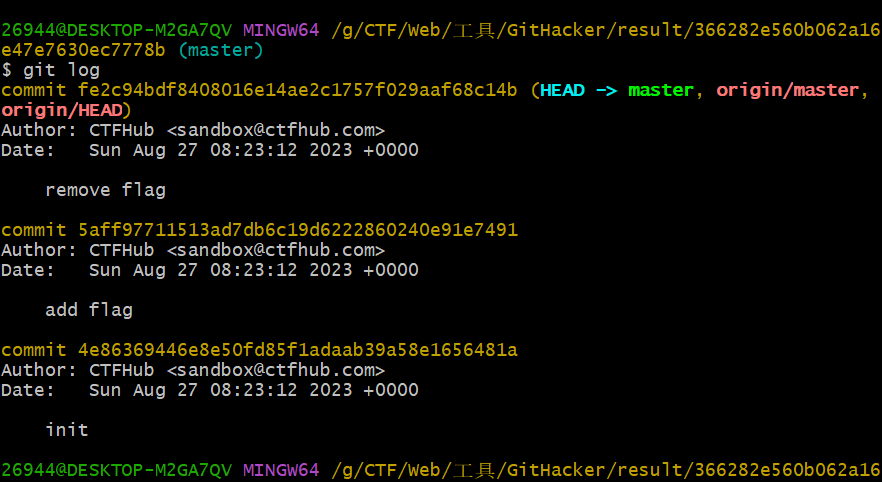
执行git diff HEAD 5aff97711513ad7db6c19d6222860240e91e7491对比与add flag版本的区别

此时有两种解题方法:
按照题意使用
git stash pop恢复文件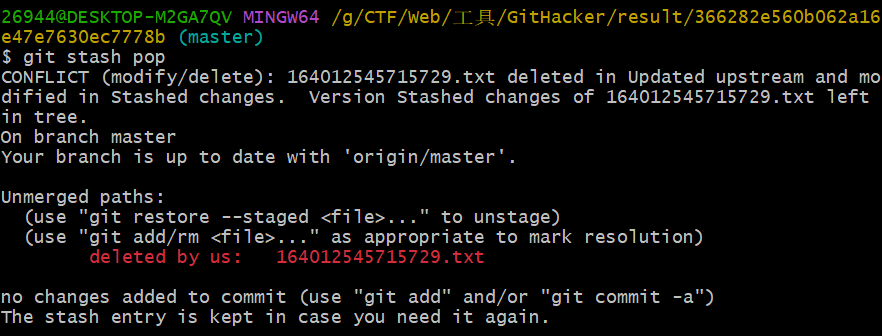
执行
git reset HEAD^回到上一个add flag的版本,此时删掉的文件也回来了
flag就在恢复的txt文件中
Index
使用GitHacker恢复源码githacker --url http://challenge-1f42ffb3a63e3f3b.sandbox.ctfhub.com:10800/.git/ --output-folder G:\CTF\Web\工具\GitHacker\result
源码目录如下
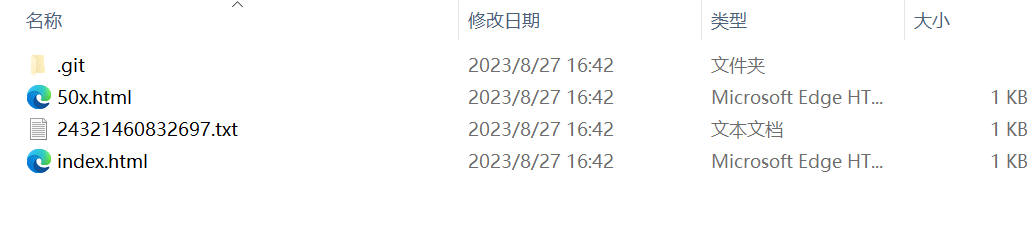
flag在txt文件中
SVN泄漏
在kali中使用dvcs-ripper工具
在result目录下执行../rip-svn.pl -v -u http://challenge-461ad970cc7dbf6b.sandbox.ctfhub.com:10800/.svn/
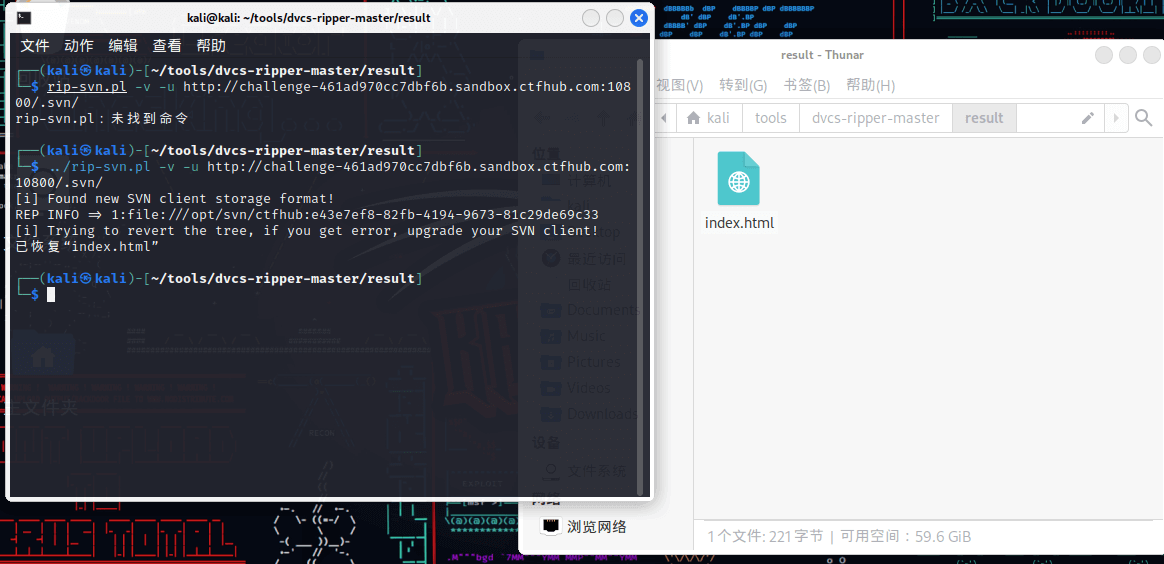
得到的源码在新建的result文件夹中

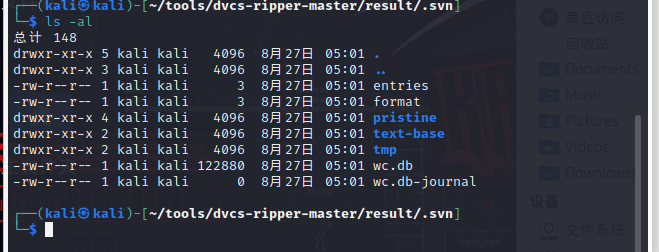
扫描后发现.svn文件夹
进入后再次扫描,发现数据库文件wc.db
执行cat wc.db | grep -a flag在其中寻找flag

grep指令
grep 指令用于查找内容包含指定的范本样式的文件,如果发现某文件的内容符合所指定的范本样式,预设 grep 指令会把含有范本样式的那一列显示出来。若不指定任何文件名称,或是所给予的文件名为 -,则 grep 指令会从标准输入设备读取数据。
1 | grep [options] pattern [files] |
- pattern - 表示要查找的字符串或正则表达式。
- files - 表示要查找的文件名,可以同时查找多个文件,如果省略 files 参数,则默认从标准输入中读取数据。
常用option参数
-a或--text: 不要忽略二进制的数据。
-i:忽略大小写进行匹配。-v:反向查找,只打印不匹配的行。-n:显示匹配行的行号。-r:递归查找子目录中的文件。-l:只打印匹配的文件名。-c:只打印匹配的行数。
并未发现有用信息后开始手动遍历目录,并在以下目录发现flag
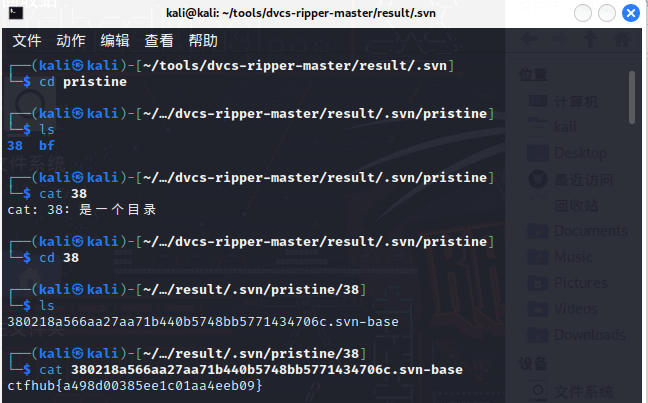
HG泄漏
在result目录下执行../rip-hg.pl -v -u http://challenge-461ad970cc7dbf6b.sandbox.ctfhub.com:10800/.hg/
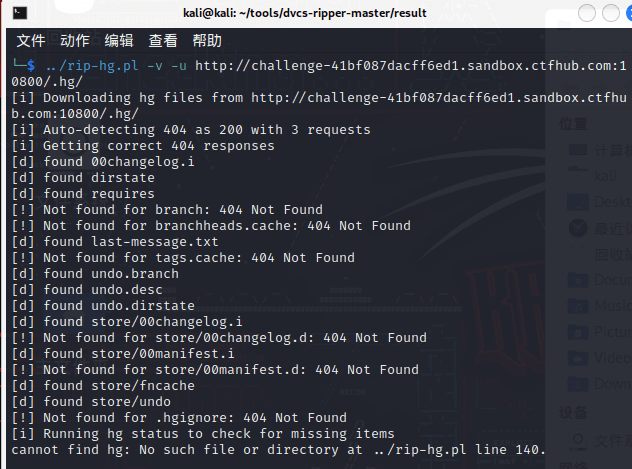
发现报错,使用ls -al扫描发现.hg文件夹依然下载成功
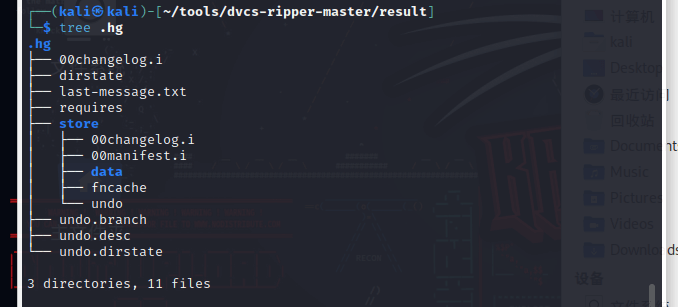
使用tree列出.hg的目录
使用grep匹配flag相关信息
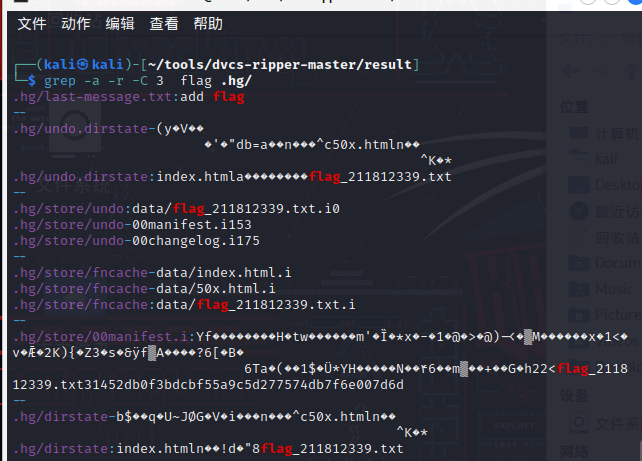
发现历史版本中存在flag_211812339.txt文件
在url后加上/flag_211812339.txt后得到flag