《动手学深度学习》笔记(前三章)
前言
上个学期搞大学生创新创业的时候,我对机器学习和OCR领域的各种方法都还是一知半解。只知道怎么看懂代码、复现代码和掌握论文的大体框架,但是对具体实现细节和原理还是一无所知。
遂趁着暑假的闲暇时光系统性学习一下深度学习
本着 学习的最高境界是能将学到的知识复述出来 这一理念,我打算在这个系列里分享一些学习笔记与收获
这次自学用到的教材是李沐老师等深度学习领域的大牛编著的《动手学深度学习(PyTorch版)》一书
本书同时覆盖深度学习的方法和实践,主要面向在校大学生、技术人员和研究人员。阅读本书需要读者了解基本的Python编程或附录中描述的线性代数、微分和概率基础。
废话不多说,本文章的笔记内容范围覆盖原书的前三章:
Chapter1.序言
序言主要是介绍机器学习,里面大体的内容还是有些浅的认知,但也有一些我觉得比较重要的知识点:
无监督学习
数据中不含有“目标”的机器学习问题通常被为无监督学习(unsupervised learning)
- 聚类(clustering)问题:没有标签的情况下,我们是否能给数据分类呢?比如,给定一组照片,我们能把它们分成风景照片、狗、婴儿、猫和山峰的照片吗?同样,给定一组用户的网页浏览记录,我们能否将具有相似行为的用户聚类呢?
- 主成分分析(principal component analysis)问题:我们能否找到少量的参数来准确地捕捉数据的线性相关属性?比如,一个球的运动轨迹可以用球的速度、直径和质量来描述。再比如,裁缝们已经开发出了一小部分参数,这些参数相当准确地描述了人体的形状,以适应衣服的需要。另一个例子:在欧几里得空间中是否存在一种(任意结构的)对象的表示,使其符号属性能够很好地匹配?这可以用来描述实体及其关系,例如“罗马” −− “意大利” ++ “法国” == “巴黎”。
- 因果关系(causality)和概率图模型(probabilistic graphical models)问题:我们能否描述观察到的许多数据的根本原因?例如,如果我们有关于房价、污染、犯罪、地理位置、教育和工资的人口统计数据,我们能否简单地根据经验数据发现它们之间的关系?
- 生成对抗性网络(generative adversarial networks):为我们提供一种合成数据的方法,甚至像图像和音频这样复杂的非结构化数据。潜在的统计机制是检查真实和虚假数据是否相同的测试,它是无监督学习的另一个重要而令人兴奋的领域。
近十年的里程碑式idea
- 新的容量控制方法,如dropout :cite:
Srivastava.Hinton.Krizhevsky.ea.2014,有助于减轻过拟合的危险。这是通过在整个神经网络中应用噪声注入 :cite:Bishop.1995来实现的,出于训练目的,用随机变量来代替权重。 - 注意力机制解决了困扰统计学一个多世纪的问题:如何在不增加可学习参数的情况下增加系统的记忆和复杂性。研究人员通过使用只能被视为可学习的指针结构 :cite:
Bahdanau.Cho.Bengio.2014找到了一个优雅的解决方案。不需要记住整个文本序列(例如用于固定维度表示中的机器翻译),所有需要存储的都是指向翻译过程的中间状态的指针。这大大提高了长序列的准确性,因为模型在开始生成新序列之前不再需要记住整个序列。 - 多阶段设计。例如,存储器网络 :cite:
Sukhbaatar.Weston.Fergus.ea.2015和神经编程器-解释器 :cite:Reed.De-Freitas.2015。它们允许统计建模者描述用于推理的迭代方法。这些工具允许重复修改深度神经网络的内部状态,从而执行推理链中的后续步骤,类似于处理器如何修改用于计算的存储器。 - 另一个关键的发展是生成对抗网络 :cite:
Goodfellow.Pouget-Abadie.Mirza.ea.2014的发明。传统模型中,密度估计和生成模型的统计方法侧重于找到合适的概率分布(通常是近似的)和抽样算法。因此,这些算法在很大程度上受到统计模型固有灵活性的限制。生成式对抗性网络的关键创新是用具有可微参数的任意算法代替采样器。然后对这些数据进行调整,使得鉴别器(实际上是一个双样本测试)不能区分假数据和真实数据。通过使用任意算法生成数据的能力,它为各种技术打开了密度估计的大门。驰骋的斑马 :cite:Zhu.Park.Isola.ea.2017和假名人脸 :cite:Karras.Aila.Laine.ea.2017的例子都证明了这一进展。即使是业余的涂鸦者也可以根据描述场景布局的草图生成照片级真实图像( :cite:Park.Liu.Wang.ea.2019)。 - 在许多情况下,单个GPU不足以处理可用于训练的大量数据。在过去的十年中,构建并行和分布式训练算法的能力有了显著提高。设计可伸缩算法的关键挑战之一是深度学习优化的主力——随机梯度下降,它依赖于相对较小的小批量数据来处理。同时,小批量限制了GPU的效率。因此,在1024个GPU上进行训练,例如每批32个图像的小批量大小相当于总计约32000个图像的小批量。最近的工作,首先是由 :cite:
Li.2017完成的,随后是 :cite:You.Gitman.Ginsburg.2017和 :cite:Jia.Song.He.ea.2018,将观察大小提高到64000个,将ResNet-50模型在ImageNet数据集上的训练时间减少到不到7分钟。作为比较——最初的训练时间是按天为单位的。 - 并行计算的能力也对强化学习的进步做出了相当关键的贡献。这导致了计算机在围棋、雅达里游戏、星际争霸和物理模拟(例如,使用MuJoCo)中实现超人性能的重大进步。有关如何在AlphaGo中实现这一点的说明,请参见如 :cite:
Silver.Huang.Maddison.ea.2016。简而言之,如果有大量的(状态、动作、奖励)三元组可用,即只要有可能尝试很多东西来了解它们之间的关系,强化学习就会发挥最好的作用。仿真提供了这样一条途径。 - 深度学习框架在传播思想方面发挥了至关重要的作用。允许轻松建模的第一代框架包括Caffe、Torch和Theano。许多开创性的论文都是用这些工具写的。到目前为止,它们已经被TensorFlow(通常通过其高级API Keras使用)、CNTK、Caffe 2和Apache MXNet所取代。第三代工具,即用于深度学习的命令式工具,可以说是由Chainer率先推出的,它使用类似于Python NumPy的语法来描述模型。这个想法被PyTorch、MXNet的Gluon API和Jax都采纳了。
原书中有一段话我觉得说的挺好的,在这里摘抄一下:
我们离一个能够控制人类创造者的有知觉的人工智能系统还很远。 首先,人工智能系统是以一种特定的、面向目标的方式设计、训练和部署的。 虽然他们的行为可能会给人一种通用智能的错觉,但设计的基础是规则、启发式和统计模型的结合。 其次,目前还不存在能够自我改进、自我推理、能够在试图解决一般任务的同时,修改、扩展和改进自己的架构的“人工通用智能”工具。
一个更紧迫的问题是人工智能在日常生活中的应用。 卡车司机和店员完成的许多琐碎的工作很可能也将是自动化的。 农业机器人可能会降低有机农业的成本,它们也将使收割作业自动化。 工业革命的这一阶段可能对社会的大部分地区产生深远的影响,因为卡车司机和店员是许多国家最常见的工作之一。 此外,如果不加注意地应用统计模型,可能会导致种族、性别或年龄偏见,如果自动驱动相应的决策,则会引起对程序公平性的合理关注。 重要的是要确保小心使用这些算法。 就我们今天所知,这比恶意超级智能毁灭人类的风险更令人担忧。
Chapter2.预备知识
数据操作
广播机制
数据操作中比较重要的一个点是广播机制:
在某些情况下,即使形状不同,我们仍然可以通过调用 广播机制(broadcasting mechanism)来执行按元素操作。 这种机制的工作方式如下:
- 通过适当复制元素来扩展一个或两个数组,以便在转换之后,两个张量具有相同的形状;
- 对生成的数组执行按元素操作。
在大多数情况下,我们将沿着数组中长度为1的轴进行广播,如下例子:
In:
1 | a = torch.arange(3).reshape((3, 1)) |
Out:
1 | (tensor([[0], |
由于a和b分别是3×1和1×2矩阵,如果让它们相加,它们的形状不匹配。 我们将两个矩阵广播为一个更大的3×2矩阵,如下所示:矩阵a将复制列, 矩阵b将复制行,然后再按元素相加。
In:
1 | a + b |
Out:
1 | tensor([[0, 1], |
节省内存
这里涉及到python中的赋值(复制)、浅拷贝与深拷贝
首先有几个关于python的基本概念要搞清楚:
变量:是一个系统表的元素,拥有指向对象的连接空间
对象:被分配的一块内存,存储其所代表的值
引用:是自动形成的从变量到对象的指针
类型:属于对象,而非变量
不可变对象:一旦创建就不可修改的对象,包括字符串、元组、数值类型
(该对象所指向的内存中的值不能被改变。当改变某个变量时候,由于其所指的值不能被改变,相当于把原来的值复制一份后再改变,这会开辟一个新的地址,变量再指向这个新的地址。)
可变对象:可以修改的对象,包括列表、字典、集合
(该对象所指向的内存中的值可以被改变。变量(准确的说是引用)改变后,实际上是其所指的值直接发生改变,并没有发生复制行为,也没有开辟新的地址,通俗点说就是原地改变。)
那么本文只会涉及赋值(复制)、浅拷贝与深拷贝三种操作的一点细微区别
即若改变新变量的值,原变量会不会随着发生变化
如下表所示:
| 操作 | 不可变对象 | 可变对象 |
|---|---|---|
| 赋值(复制) | 不变 | 变化 |
| 浅拷贝 | 不变 | 变化 |
| 深拷贝 | 不变 | 不变 |
如果想更深入的了解这三种操作,可以参考以下信息提示:
直接赋值其实就是对象的引用(别名)。


拷贝父对象,不会拷贝对象的内部的子对象。
浅拷贝要分两种情况进行讨论:
1)当浅拷贝的值是不可变对象(字符串、元组、数值类型)时和“赋值”的情况一样,对象的id值(id()函数用于获取对象的内存地址)与浅拷贝原来的值相同。
2)当浅拷贝的值是可变对象(列表、字典、集合)时会产生一个“不是那么独立的对象”存在。



copy 模块的 deepcopy 方法,完全拷贝了父对象及其子对象。
改变原有被复制对象不会对已经复制出来的新对象产生影响。


那么事实上,在pytorch中,张量作为可变对象来看待
那么像x.reshape()和x.detach()这样的操作具有浅拷贝的性质:

而运行一些操作也可能会导致为新结果分配内存。
例如,如果我们用Y = X + Y,我们将取消引用Y指向的张量,而是指向新分配的内存处的张量。
在下面的例子中,我们用Python的id()函数演示了这一点, 它给我们提供了内存中引用对象的确切地址。 运行Y = Y + X后,我们会发现id(Y)指向另一个位置。 这是因为Python首先计算Y + X,为结果分配新的内存,然后使Y指向内存中的这个新位置。
In :
1 | before = id(Y) |
Out:
1 | False |
这可能是不可取的,原因有两个:
- 首先,我们不想总是不必要地分配内存。在机器学习中,我们可能有数百兆的参数,并且在一秒内多次更新所有参数。通常情况下,我们希望原地执行这些更新;
- 如果我们不原地更新,其他引用仍然会指向旧的内存位置,这样我们的某些代码可能会无意中引用旧的参数。
幸运的是,(执行原地操作)非常简单。 我们可以使用切片表示法将操作的结果分配给先前分配的数组,例如Y[:] = <expression>。 为了说明这一点,我们首先创建一个新的矩阵Z,其形状与另一个Y相同, 使用zeros_like来分配一个全00的块。
In :
1 | Z = torch.zeros_like(Y) |
Out:
1 | id(Z): 139931132035296 |
[如果在后续计算中没有重复使用X, 我们也可以使用X[:] = X + Y或X += Y来减少操作的内存开销。]
In :
1 | before = id(X) |
Out:
1 | True |
深拷贝
而如果我们如果想对张量进行深拷贝,则可以使用clone()函数:
In:
1 | a = torch.arange(12) |
Out:
1 | tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]) |
而关于张量的浅拷贝和深拷贝其实还有一些更深入的区别:
.clone()是深拷贝,开辟新的存储地址而不是引用来保存旧的tensor,在梯度回传的时候clone()充当中间变量,会将梯度传给源张量进行叠加,但是本身不保存其grad,值为None。.detach()是浅拷贝,新的tensor会脱离计算图,不会牵扯梯度计算。

线性代数
降维
1 | A = torch.arange(20, dtype=torch.float32).reshape(5, 4) |
默认情况下,调用求和函数会沿所有的轴降低张量的维度,使它变为一个标量。 我们还可以[指定张量沿哪一个轴来通过求和降低维度]。 以矩阵为例,为了通过求和所有行的元素来降维(轴0),可以在调用函数时指定axis=0。 由于输入矩阵沿0轴降维以生成输出向量,因此输入轴0的维数在输出形状中消失。
In :
1 | A_sum_axis0 = A.sum(axis=0) |
Out:
1 | (tensor([40., 45., 50., 55.]), torch.Size([4])) |
指定axis=1将通过汇总所有列的元素降维(轴1)。因此,输入轴1的维数在输出形状中消失。
In :
1 | A_sum_axis1 = A.sum(axis=1) |
Out:
1 | (tensor([ 6., 22., 38., 54., 70.]), torch.Size([5])) |
沿着行和列对矩阵求和,等价于对矩阵的所有元素进行求和。
In:
1 | A.sum(axis=[0, 1]) # 结果和A.sum()相同 |
Out:
1 | tensor(190.) |
非降维求和
但是,有时在调用函数来[计算总和或均值时保持轴数不变]会很有用。
In:
1 | sum_A = A.sum(axis=1, keepdims=True) |
Out:
1 | tensor([[ 6.], |
例如,由于sum_A在对每行进行求和后仍保持两个轴,我们可以(通过广播将A除以sum_A)。
In:
1 | A / sum_A |
Out:
1 | tensor([[0.0000, 0.1667, 0.3333, 0.5000], |
如果我们想沿[某个轴计算A元素的累积总和], 比如axis=0(按行计算),可以调用cumsum函数。 此函数不会沿任何轴降低输入张量的维度。
In:
1 | A.cumsum(axis=0) |
Out:
1 | tensor([[ 0., 1., 2., 3.], |
范数
类似于向量的$L_2$范数,[矩阵]$\mathbf{X} \in \mathbb{R}^{m \times n}$(的Frobenius范数(Frobenius norm)是矩阵元素平方和的平方根:
$|\mathbf{X}|F = \sqrt{\sum{i=1}^m \sum{j=1}^n x{ij}^2}.$
Frobenius范数满足向量范数的所有性质,它就像是矩阵形向量的$L_2$范数。 调用以下函数将计算矩阵的Frobenius范数。
In:
1 | torch.norm(torch.ones((4, 9))) |
Out:
1 | tensor(6.) |
自动求导、反向传播、梯度下降(重点)
这里其实是理解深度学习时最关键的一个知识点,基本上如果能将这一部分搞清楚,那么之后自己训练模型的时候也能更胸有成竹一些,而不是仅仅成为一个“调参小子”(仿照“脚本小子”的叫法🤣
脚本小子(英语:script kiddie)是一个贬义词,用来描述以“黑客”自居并沾沾自喜的初学者。脚本小子不像真正的黑客那样发现系统漏洞,他们通常使用别人开发的程序来恶意破坏他人系统。通常的刻板印象为一位没有专科经验的少年,破坏无辜网站企图使得他的朋友感到惊讶,因而称之为脚本小子。
脚本小子常常从某些网站上复制脚本代码,然后到处粘贴,却并不一定明白它们的方法与原理。他们钦慕于黑客的能力与探索精神,但与黑客所不同的是,脚本小子通常只是对计算机系统有基础了解与爱好,但并不注重程序语言、算法和数据结构的研究,虽然这些对于真正的黑客来说是必须具备的素质。
在学习了原书以及一些在线资料之后,我分享一下自己对自动求导、反向传播和梯度下降这几个概念的理解
以下内容均为个人理解,如有纰漏或者有更好的表达请在评论区指出😊
我们都知道,深度学习的最终目标是找到一组最终的参数,使得当前的损失函数(Loss Function)最小
那么这里其实可以简化为一个求函数最小值的问题,此时网络的中间参数为自变量,损失函数的值为因变量
其实如果自变量只有一个,那么此时问题就变成了在直角坐标系的曲线上寻找最低点的问题,我们只需要找到x使得导数$\frac{\partial y(x)}{\partial x} = 0$,那么此处的因变量值y就为函数的局部最小值
由于真实的神经网络结构中中间参数的个数很多,我们需要将自变量推广为一个向量,而此时导数则推广为梯度
梯度(gradient)的本意是一个向量(矢量),表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向(此梯度的方向)变化最快,变化率最大(为该梯度的模)。
当y为标量,x为向量时
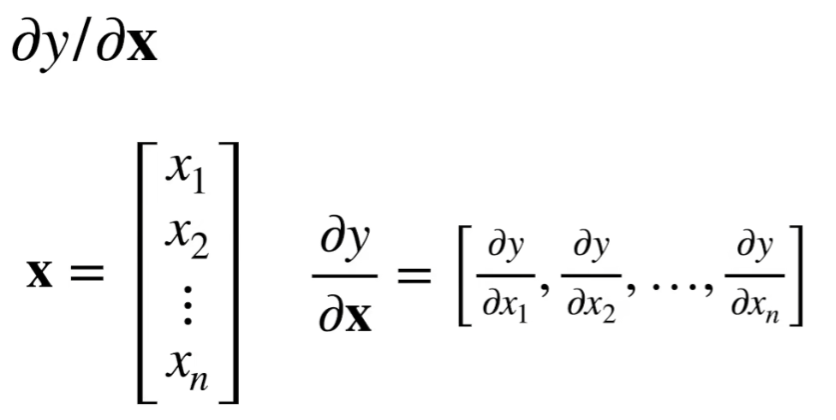
当y和x均为向量时
但是很多情况下,并不能直接找到令梯度为0的值,所以只能够逐渐调整中间参数,使得损失函数的值不断减小
此时就要用到梯度下降法
梯度这个概念的名称其实非常直观,我们可以将它与山脉的坡度类比⛰
当我们需要下山到山谷时,如果沿着坡度的反方向走,下山的速度是最快的
所以当我们每次需要调整中间参数时,可以用它减去学习率乘以梯度向量取反,这里的学习率可以与下山时走路的步长类比
而更新参数的具体细节是如何实现的呢?
此时需要用到反向传播算法
这里的反向二字其实就是指损失函数对参数的梯度通过网络反向流动
而通过利用链式法则,可以计算出损失函数对各参数的梯度,具体公式这里就不涉及了

而该如何更高效地计算梯度呢?
这里涉及到自动求导的概念,自动求导是基于计算图的
计算图被定义为有向图,其中节点对应于数学运算。 计算图是表达和评估数学表达式的一种方式。
例如,这里有一个简单的数学公式 -
1 | p = x + y |
我们可以绘制上述方程的计算图如下。
上面的计算图具有一个加法节点(具有“+”符号的节点),其具有两个输入变量x和y以及一个输出q。
让我们再举一个例子,稍微复杂些。如下等式。
1 | g = ( x + y ) ∗ z |
以上等式由以下计算图表示。

通过一次前向累积和一次反向累积,就能在保证速度的条件下完成自动求导

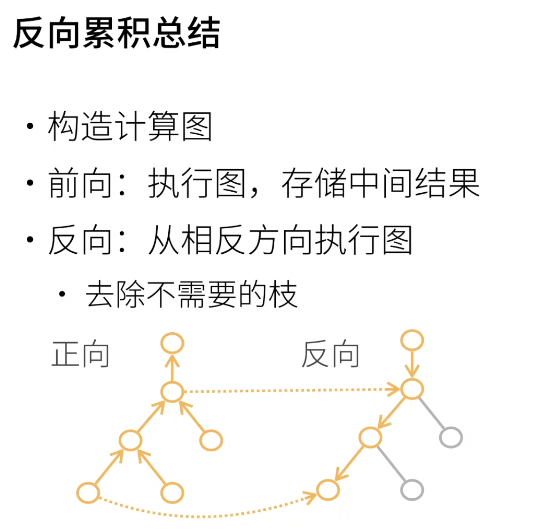

在Pytorch中,这一过程是隐式进行的,只需要我们在设定参数时注明以下代码:
1 | x.requires_grad_(True) |
以下是一个如何使用反向传播的示例:
In:
1 | import torch |
Out:
1 | tensor([0., 4., 8., 12.]) |
如果想要加深对这几个概念的理解,下面这几个视频也讲的还不错
自动求导:https://www.bilibili.com/video/BV1yG411x7Cc
Chapter3.线性神经网络
线性回归
小批量随机梯度下降

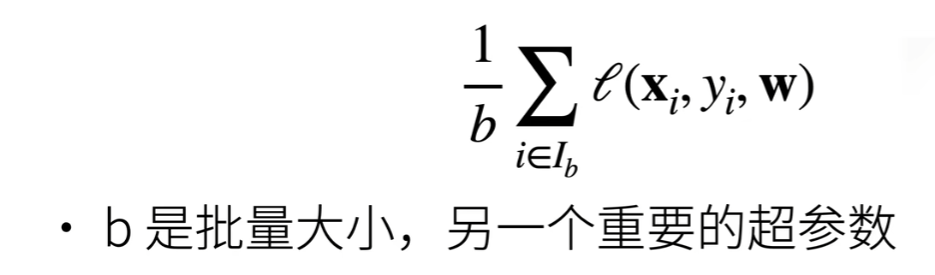
选择批量大小时

具体过程
优化算法
小批量随机梯度下降:
在每一步中,使用从数据集中随机抽取的一个小批量,然后根据参数计算损失的梯度。 接下来,朝着减少损失的方向更新我们的参数。 下面的函数实现小批量随机梯度下降更新。 该函数接受模型参数集合、学习速率和批量大小作为输入。每 一步更新的大小由学习速率
lr决定。 因为我们计算的损失是一个批量样本的总和,所以我们用批量大小(batch_size) 来规范化步长,这样步长大小就不会取决于我们对批量大小的选择1
2
3
4
5
6def sgd(params, lr, batch_size): #@save
"""小批量随机梯度下降"""
with torch.no_grad():
for param in params:
param -= lr * param.grad / batch_size
param.grad.zero_()每个batch计算时,需要使用x.grad.zero_()把梯度先清零(此处x为特征参数),若不清零,则
下次调用x.grad时会在之前梯度数值上累加。
训练流程:
执行以下循环:
- 初始化参数
- 重复以下训练,直到完成
- 计算梯度$\mathbf{g} \leftarrow \partial{(\mathbf{w},b)} \frac{1}{|\mathcal{B}|} \sum{i \in \mathcal{B}} l(\mathbf{x}^{(i)}, y^{(i)}, \mathbf{w}, b)$
- 更新参数$(\mathbf{w}, b) \leftarrow (\mathbf{w}, b) - \eta \mathbf{g}$
具体代码:
In:
1
2
3
4
5
6
7
8
9
10
11
12
13
14lr = 0.03
num_epochs = 3
net = linreg
loss = squared_loss
for epoch in range(num_epochs):
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w, b), y) # X和y的小批量损失
# 因为l形状是(batch_size,1),而不是一个标量。l中的所有元素被加到一起,
# 并以此计算关于[w,b]的梯度
l.sum().backward()
sgd([w, b], lr, batch_size) # 使用参数的梯度更新参数
with torch.no_grad():
train_l = loss(net(features, w, b), labels)
print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')Out:
1
2
3epoch 1, loss 0.043705
epoch 2, loss 0.000172
epoch 3, loss 0.000047
使用with torch.no_grad():的原因
有一些任务,可能事先需要设置,事后做清理工作。对于这种场景,Python的with语句提供了一种非常方便的处理方式。其中一个很好的例子是文件处理,你需要获取一个文件句柄,从文件中读取数据,然后关闭文件句柄。
with 语句适用于对资源进行访问的场合,确保不管使用过程中是否发生异常都会执行必要的“清理”操作,释放资源,比如文件使用后自动关闭/线程中锁的自动获取和释放等。
例如:
1 | file = open("1.txt") |
存在问题如下:
(1)文件读取发生异常,但没有进行任何处理;
(2)可能忘记关闭文件句柄;
初步改进:
1 | try: |
虽然上面这段代码运行良好,但比较冗长。
而使用with的话,能够减少冗长,还能自动处理上下文环境产生的异常。如下面代码:
1 | with open("1.txt") as file: |
总结with工作原理:
(1)紧跟with后面的语句被求值后,返回对象的“–enter–()”方法被调用,这个方法的返回值将被赋值给as后面的变量;
(2)当with后面的代码块全部被执行完之后,将调用前面返回对象的“–exit–()”方法。
了解了python中with语句的用法,那么此处的torch.no_grad()就是作为后面代码块的执行条件
而torch.no_grad()的作用就是使所有计算得出的tensor的requires_grad都自动设置为False,这样可以大大减少显存或内存占用。
现在我们可以找找前面线性回归的过程中有哪些位置用到了torch.no_grad()
一处是小批量随机梯度下降,一处是计算训练时的中间结果,由于我们不需要这两个过程中产生的新tensor自动求导,所以我们将其放在torch.no_grad()的条件下
简洁实现
读取数据集使用TensorDataset和DataLoader函数
线性回归使用Linear函数
损失函数使用MSELoss函数
- 小批量随机梯度下降使用optim.SGD函数
softmax回归

softmax函数
softmax函数能够将未规范化的预测变换为非负数并且总和为1,同时让模型保持 可导的性质。 为了完成这一目标,我们首先对每个未规范化的预测求幂,这样可以确保输出非负。 为了确保最终输出的概率值总和为1,我们再让每个求幂后的结果除以它们的总和。如下式:
$\hat{\mathbf{y}} = \mathrm{softmax}(\mathbf{o})\quad \text{其中}\quad \hat{y}_j = \frac{\exp(o_j)}{\sum_k \exp(o_k)}$
exp() 是一个指数函数,用来求 e(底数)的 x 次幂(次方)的值。
1 | exp(4) = 54.598150 |
这里,对于所有的$𝑗$总有$0 \leq \hat{y}_j \leq 1$。 因此,$\hat{\mathbf{y}}$可以视为一个正确的概率分布。 softmax运算不会改变未规范化的预测$𝐨$之间的大小次序,只会确定分配给每个类别的概率。 因此,在预测过程中,我们仍然可以用下式来选择最有可能的类别。
$\operatorname{argmax}_j \hat y_j = \operatorname{argmax}_j o_j.$
尽管softmax是一个非线性函数,但softmax回归的输出仍然由输入特征的仿射变换决定。 因此,softmax回归是一个线性模型(linear model)。
具体过程
训练集数据读取的速度应该要设定得比模型训练的速度要快
实现softmax函数
实现softmax函数由三个步骤组成:
- 对每个项求幂(使用
exp); - 对每一行求和(小批量中每个样本是一行),得到每个样本的规范化常数;
- 将每一行除以其规范化常数,确保结果的和为1。
代码如下:
1 | def softmax(X): |
定义损失函数
这里的交叉熵损失函数在定义时用到了花式索引的概念
花式索引(Fancy indexing)是指利用整数数组进行索引,这里的整数数组可以是Numpy数组也可以是Python中列表、元组等可迭代类型。
当使用花式索引访问一维数组时,程序会将花式索引对应的数组或列表的元素作为索引,依次根据各个索引获取对应位置的元素,并将这些元素以数组的形式返回。
代码示例如下:
In:
1 | import numpy as np |
Out:
1 | [1 2 3 4 5 6 7 8 9] |
当使用花式索引访问二维数组时,程序会将花式索引对应的数组或列表的元素作为索引,依次根据各个索引获取对应位置的一行元素,并将这些行元素以数组的形式返回。
代码示例如下:
In:
1 | import numpy as np |
Out:
1 | [[1 2 3] |
需要说明的是,在使用两个花式索引,即通过“二维数组 [ 花式索引 , 花式索引 ]”的形式访问数组时,会将第一个花式索引对应数组或列表的各元素作为行索引,将第二个花式索引对应数组或列表的各元素作为列索引,再按照“二维数组 [ 行索引 , 列索引 ]”的形式获取对应位置的元素。例如,使用两个花式索引访问二维数组 array_2d 的元素,代码如下:
In:
1 | # 使用两个花式索引访问元素 |
Out:
1 | [2 8] |
上述与二维数组相关的花式索引操作的示意如图:

我们只需一行代码就可以[实现交叉熵损失函数]:
1 | def cross_entropy(y_hat, y): |
计算精度
为了计算精度,我们执行以下操作。 首先,如果y_hat是矩阵,那么假定第二个维度存储每个类的预测分数。 我们使用argmax获得每行中最大元素的索引来获得预测类别。 然后我们[将预测类别与真实y元素进行比较]。 由于等式运算符“==”对数据类型很敏感, 因此我们将y_hat的数据类型转换为与y的数据类型一致。 结果是一个包含0(错)和1(对)的张量。 最后,我们求和会得到正确预测的数量。
1 | def accuracy(y_hat, y): #@save |
简洁实现
- 损失函数使用nn.CrossEntropyLoss函数